3. Architectuur#
3.1. Introductie#
3.1.1. Een ‘computer’#

Fig. 3.1 Een vroege computer slechts#
geschikt voor één enkele taak
Het woord computer komt van computare wat berekenen betekent. Tot zo’n honderd jaar geleden was het woord computer een functieomschrijving voor mensen die berekeningen deden. Het apparaat computer was in het begin ook niet veel meer dan een apparaat wat berekeningen deed. De eerste computers werden gebouwd met een specifiek doel voor ogen. Een voorbeeld daarvan zijn simpele rekenmachines. Deze computers konden alleen berekeningen uitvoeren waar ze op gebouwd waren. Dat betekende dat je een apart apparaat moest hebben, wanneer je verschillende soorten berekeningen wilde uitvoeren.
Dit veranderde ten tijde van de Tweede Wereldoorlog. De Britten en de Amerikanen waren onafhankelijk van elkaar bezig met het conceptualiseren van een computer die niet voor 1 doel gebouwd was, maar die geherprogrammeerd kon worden. In het Verenigd Koninkrijk was dit Alan Turing in 1936 met zijn ideeën over een universal machine. In de Tweede Wereldoorog ging Turing voor de Britse overheid werken om de codes van de Duitsers te kraken. Om te helpen bij het kraken van de Duitse encryptiemethode Enigma, zijn de bombes gebouwd. Dit waren computers, geschikt voor één enkele taak. Dit was best revolutionair. Tot die tijd werden codes met pen, papier en wat codeboeken gekraakt. Handwerk dus. De Enigma-codes waren zo moeilijk, dat handwerk niet meer toereikend was. Deze van klikkende relais gebouwde bombes, maakten gebruik van logica en statistiek. Bij het kraken van een nog moeilijkere Duitse encryptiemethode, kon de bombe niet meer gebruikt worden. De Colossus werd ontworpen. Hierbij werd niet meer gebruik gemaakt van relais, maar van electronenbuizen. De Britten waren er met de Colossus in geslaagd om een programmeerbare computer te bouwen, twee jaar voordat de Amerikanen dat lukte. Dit gebeurde alleen in het diepste geheim, omdat deze computers een belangrijke rol speelden in de oorlog.

Fig. 3.2 De Colossus in Bletchley Park#
In de Verenigde Staten waren het de wetenschappers Eckert en Mauchly die zich bezig hielden met een concept voor het opslaan van programma’s in herprogrammeerbaar geheugen. Von Neumann ging met dit concept aan de haal en publiceerde het werk van de heren onder zijn naam. Daarom kennen we nu het begrip “von Neumann principe”. Uiteindelijk slaagden de Amerikanen erin om de ENIAC te bouwen. De ENIAC was niet alleen programmeerbaar, maar ook herprogrammeerbaar. De Amerikaanse belastingbetaler werd voorgeschoteld dat de ENIAC gebruikt werd voor het berekenen van weersvoorspelling. Dit was ook de dagtaak van de ENIAC. Maar ’s nachts werd de ENIAC in het geheim gebruikt door het Amerikaanse leger om berekeningen te maken voor de ontwikkeling van H-bommen (een atoombom op basis van waterstof).

Fig. 3.3 De ENIAC#
3.1.2. De basis van een computer#
Tegenwoordig gebruiken we het woord computer voor een apparaat dat een invoer kan verwerken met behulp van opgeslagen instructies, en het resultaat als uitvoer geeft. Dit noemen we ook wel het von Neumann principe: invoer, opslag, verwerking, en uitvoer.
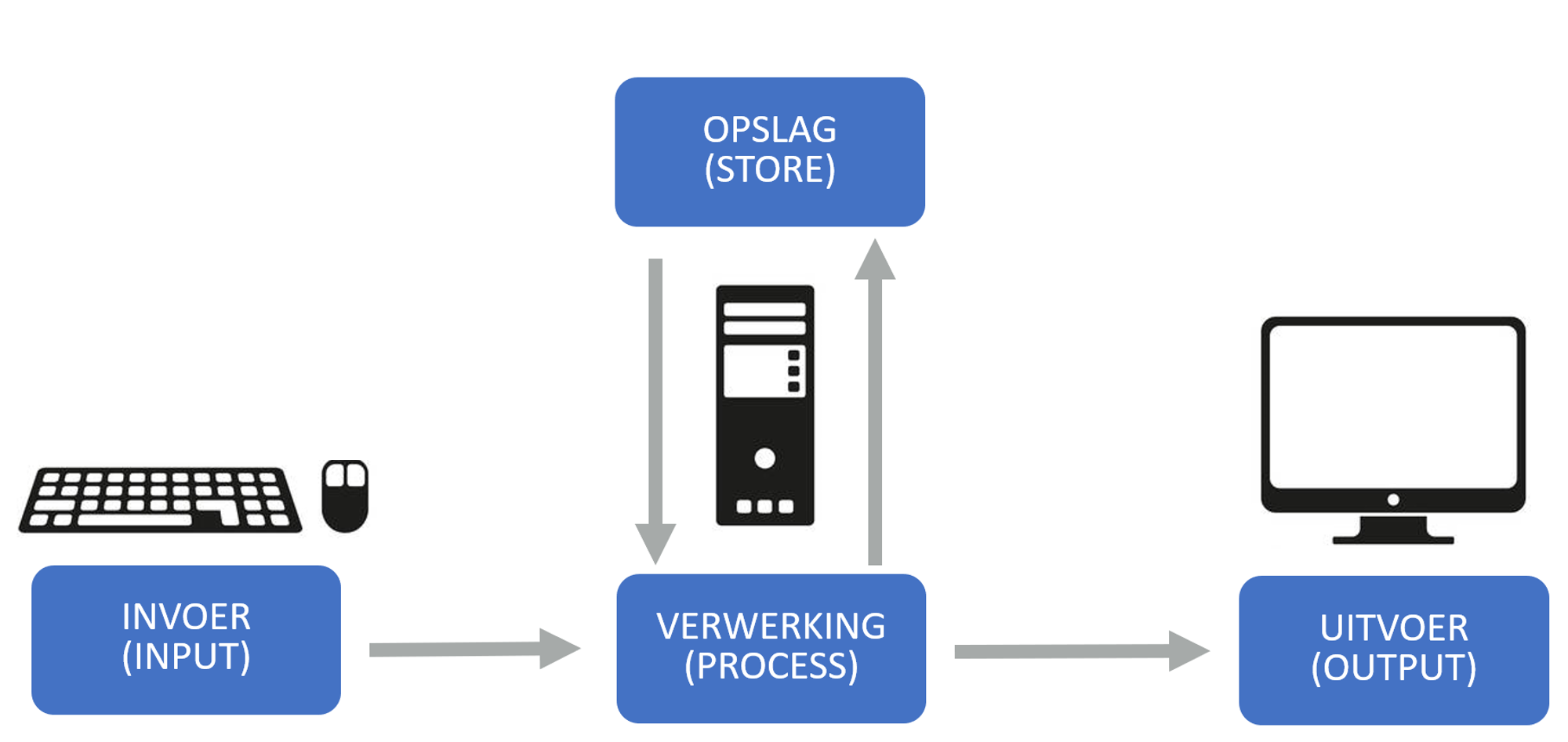
Fig. 3.4 Het schema van de von Neumann architectuur#
De invoer is de manier waarop de gebruiker signalen naar de computer stuurt. Dit kan bijvoorbeeld het indrukken van een toets of het verschuiven van een muis zijn.
De verwerking neemt deze invoer en maakt daar berekeningen mee. Welke berekeningen gedaan worden is afhankelijk van het opgeslagen programma. Dit programma zijn de instructies die in de opslag bewaard staan. Dit kan bijvoorbeeld een berekening zijn die de ingetoetste letter verwerkt en de bijbehorende pixels berekent om die letter weer te geven, of bijvoorbeeld een berekening die de nieuwe positie van de cursor uitrekent. De opslag noemen we ook wel het geheugen. In dit geheugen worden zowel instructies als data opgeslagen.
De uitvoer is de manier waarop de computer de resultaten van de berekeningen teruggeeft aan de gebruiker. Bijvoorbeeld het beeldscherm, waar letters op verschijnen of een cursor beweegt door andere pixels te laten branden. Dit kan de gebruiker dan weer zien.
Tip
Bekijk ook de video “How computers work: CPU, Memory, Input & Output” van (http://code.org). Nederlandse ondertiteling aanwezig.
3.1.3. Een stukje technischer#
De uitwerking van het von Neumann principe leidt tot een computerarchitectuur die verschillende onderdelen bevat. Die onderdelen werken samen om een programma uit te voeren. Vooral de verwerkingseenheid heeft een hoop verschillende onderdelen. Elk van die onderdelen heeft zijn eigen taakje.
Het geheugen (memory) is een opslagplek met heel veel vakjes. Ieder vakje kan een beperkte hoeveelheid data bevatten. De data in de vakjes zijn instructies voor een processor. De processor verwerkt de data en maakt op basis daarvan berekeningen en keuzes. Meerdere instructies samen vormen een computerprogramma.
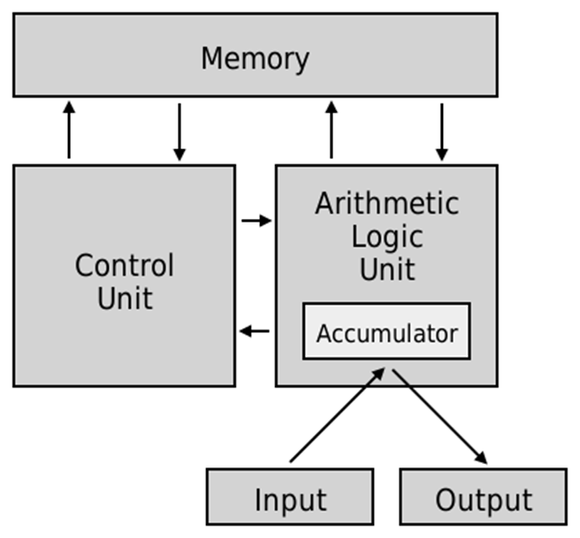
Control Unit: De CU zorgt ervoor dat instructies één voor één opgehaald worden uit het geheugen, uitgevoerd worden, en dat eventueel data terug naar het geheugen verplaatst wordt om op te slaan.
Arithmetic and Logic Unit: De ALU kan twee waardes bij elkaar optellen of van elkaar af halen en kan simpele logische instructies uitvoeren.
Accumulator: kan tijdelijk een waarde onthouden. Hier wordt de uitkomst van de ALU bewaard totdat deze in het geheugen gezet kan worden. Invoer (input) komt ook eerst in de accumulator te staan zodat deze verwerkt kan worden, en ook resultaten van een berekening worden vanuit de accumulator als uitvoer (output) gegeven.
3.1.4. Even opfrissen#
De onderdelen die in een computer zitten hebben jullie al bij Basis van Computer Science eens eerder gezien. We gaan ons in de komende paragrafen verdiepen in deze onderdelen en kijken hoe ze nou precies samenwerken. Dit doen we met de von Neumann architectuur in ons achterhoofd.

Oefening 3.1
Benoem de onderdelen in bovenstaand figuur
3.2. De processor#
3.2.1. Berekenaar#
Elke aanpassing of verandering die met een computer gedaan wordt is in feite een berekening. Deze berekeningen worden gedaan door de processor. Die processor is dus eigenlijk het brein van de computer. De processor is non-stop aan het rekenen. Dat vraagt een hoop energie. Wanneer we energie omzetten dan komt daar ook warmte bij vrij. Hoe harder de processor moet werken, hoe meer energie-omzetting, hoe meer warmte er gegenereerd wordt. De processor kan zelfs oververhit raken, daarom moet hij goed gekoeld worden.
De processor is dus de verwerkingseenheid in de von Neumann architectuur. Die zorgt ervoor dat de invoer die de gebruiker geeft wordt verwerkt tot een resulterende uitvoer. De Engels term voor processor is Central Processing Unit (CPU).
3.2.2. Transistoren en instructies#
Een processor moet continu berekeningen doen. Die berekeningen gebeuren door stroompjes te laten lopen door schakelaars en logische schakelingen. Die schakelaars noemen we transistoren. Dat zijn elektrische componenten die stroom wel (1) of niet (0) door laten. Hoe die logische schakelingen en schakelaars samenwerken om berekeningen te maken is behandeld in het vorige hoofdstuk. Wanneer we de logische schakelingen van de NOT, AND, en OR poort uittekenen dan worden de transistoren meestal weergegeven met een cirkel waar 3 lijnen in samenkomen.
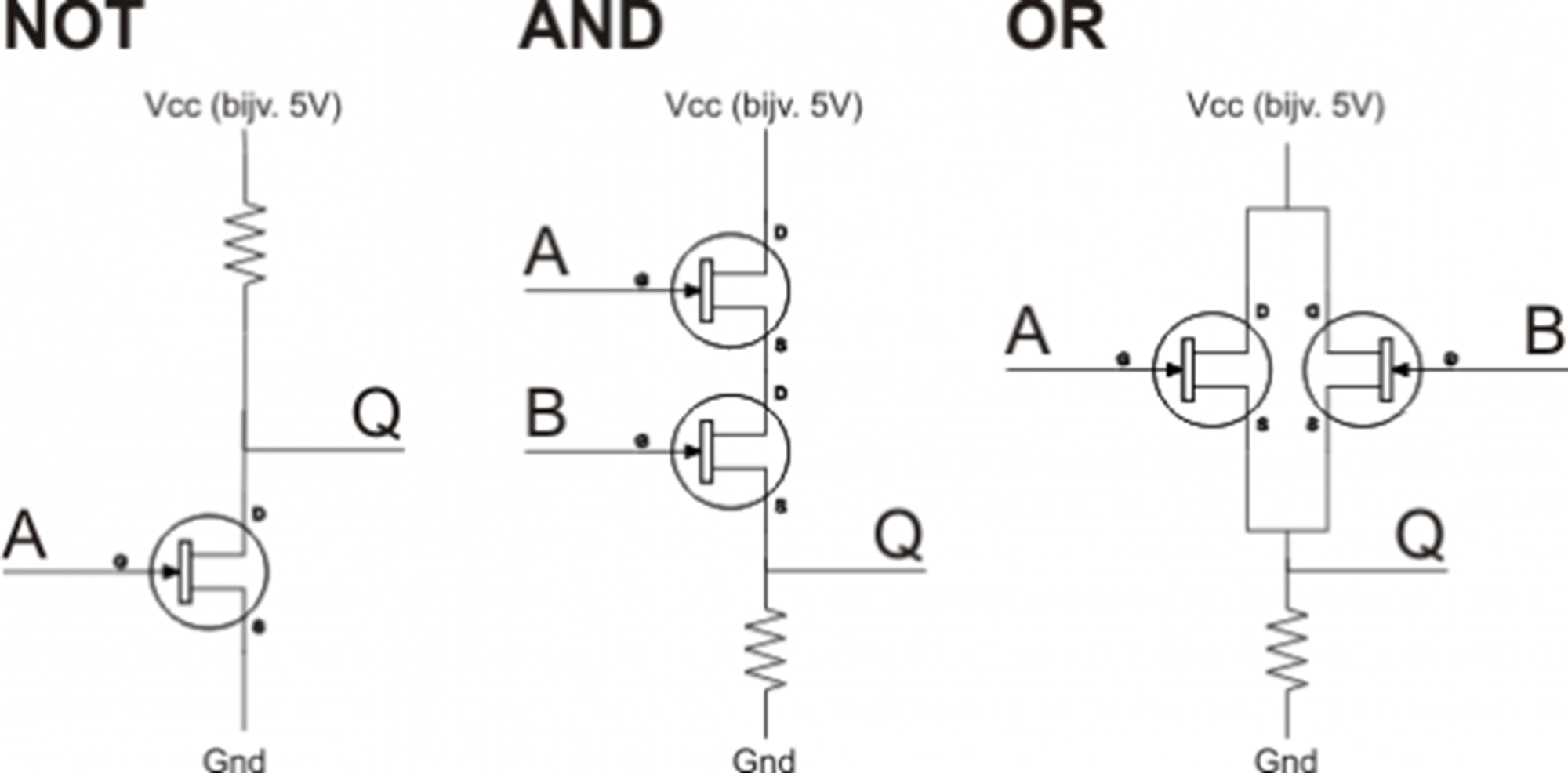
Fig. 3.5 Logische poorten gemaakt met transistoren#
De voorloper van de transistor was de elektronenbuis. Een grote glazen vacuümbuis die wel iets weg had van een gloeilamp. Deze vacuümbuizen werden gebruikt om elektrische signalen te versterken. Dit was vooral handig voor het oppikken van zwakke radiosignalen in de lucht. Door deze signalen met een vacuümbuis te versterken konden de radiosignalen in de lucht hoorbaar gemaakt worden. De huidige transistoren kunnen nog steeds elektrische signalen versterken maar in de processor is hun doel om elektrische signalen aan en uit te zetten om zo eentjes en nulletjes te maken.

Fig. 3.6 Vlnr: vacuümbuis, transistor, IC en SMD IC#
De eerste vacuümbuizen waren nog groter dan je hand en ze werden heel warm. Niet erg praktisch dus. Met de komst van de transistor was zo’n schakelaar ineens kleiner dan een vinger, en ze werden ook niet meer zo warm. De technologie ging snel vooruit, en de transistoren werden zo klein dat er chips kwamen waar steeds meer transistoren op pasten. Die vooruitgang staat bekent als de Wet van Moore. Iedere 2 jaar verdubbelt het aantal transistoren op dezelfde microchip-oppervlakte. Op deze manier verdubbelt de rekenkracht dus iedere twee jaar, een exponentiële toename. Tegenwoordig (2023) maken we al processoren op een schaalgrootte van 5\(nm\). Dat wil zeggen dat de transistoren slechts enkele atomen groot zijn. Voor de mensen, die al wat meer natuurkunde en quantumtheorie hebben gehad: op deze schaal moet je als ontwerper rekening houden met bizarre quantumverschijnselen, zoals het tunneleffect.
Tip
Bekijk ook de video “De transistor: een schakelaar voor de moderne tijd” van Schooltv
3.2.3. ALU, CU, Registers#
In de vorige paragraaf heb je gezien dat wanneer we het Von Neumann-principe uitwerken, daar verschillende benodigdheden uit ontstaan. Het geheugen (memory) was hier een onderdeel van. Daar gaan we bij Geheugen verder op in. De andere benodigdheden bevinden zich in de processor (Central Processing Unit). De Control Unit en de Arithmetic/Logic Unit zijn al besproken. We herhalen ze nog even.
Control Unit: De CU zorgt ervoor dat instructies één voor één opgehaald worden uit het geheugen, uitgevoerd worden, en dat eventueel data terug naar het geheugen verplaatst wordt om op te slaan.
Arithmetic and Logic Unit: De ALU kan twee waardes bij elkaar optellen of van elkaar af halen en kan simpele logische instructies uitvoeren.
Accumulator: kan tijdelijk een waarde onthouden. Hier wordt de uitkomst van de ALU bewaard totdat deze in het geheugen gezet kan worden. Invoer (input) komt ook eerst in de accumulator te staan zodat deze verwerkt kan worden, en ook resultaten van een berekening worden vanuit de accumulator als uitvoer (output) gegeven.
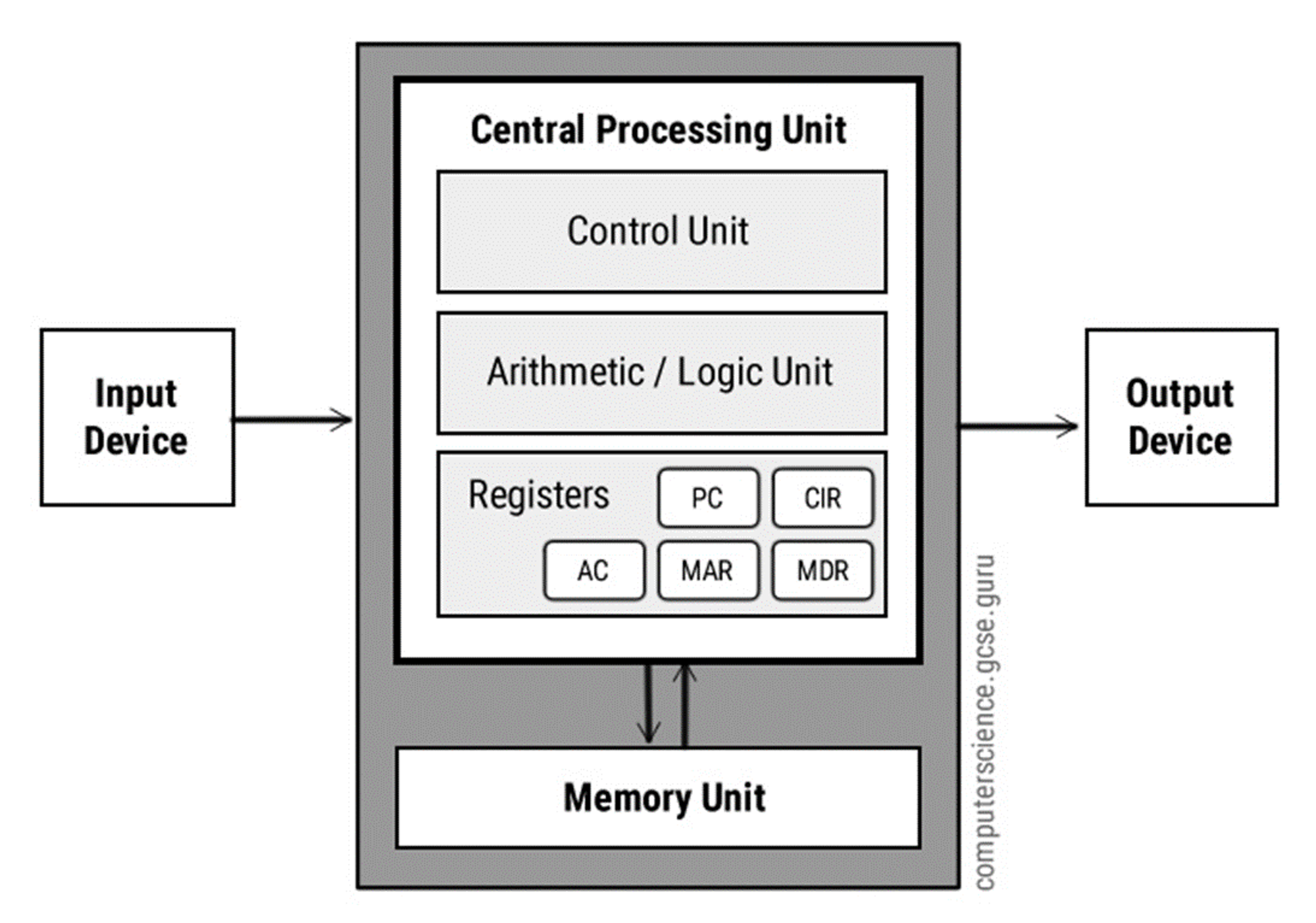
Fig. 3.7 Schema van een CPU#
Nu iets nieuws: Dit tijdelijk onthouden van data gebeurt met registers. Een register die je al kent is de accumulator, maar er zijn er nog meer. Al deze registers bewaren tijdelijk een waarde of instructie. Bijvoorbeeld wanneer deze uit het geheugen opgehaald is of wanneer er iets terug in het geheugen geplaatst moet worden.
Program Counter: houdt bij wat het volgende vakje in het geheugen is die uitgevoerd moet worden. Ieder vakje in het geheugen kan bepaalde waardes op slaan. Wat die waardes betekenen is verschillend. Zo kan een vakje een instructie bevatten (bijvoorbeeld optellen of aftrekken), een doeladres van een ander geheugenvakje bevatten, of een getal bevatten (bijvoorbeeld 17 of 88).
Current Instruction Register (CIR): Wanneer een geheugenvakje een instructie bevat dan wordt deze instructie even tijdelijk naar de CIR gestuurd zodat de instructie vanaf daar verwerkt en uitgevoerd kan worden. Dit kan bijvoorbeeld een instructie zijn dat de waarde van de accumulator in een geheugenvakje geschreven moet worden. Of dat het getal in een geheugenvakje bij de accumulator opgeteld moet worden.
Memory Address Register (MAR): In de voorbeelden die hier voor de CIR gegeven worden is er dus nog een ander geheugenvakje nodig. Dit is het doelvakje voor de instructie. Wanneer de processor een instructie gaat uitvoeren zoals het lezen of schrijven van data, dan staat er in de MAR wat het adres van het doelvakje is en welk geheugenvakje er dan dus gelezen of beschreven gaat worden.
Memory Data Register (MDR): Ook de data die gelezen of geschreven wordt, gaat naar een register. Dit register bewaart dus geen instructies of adressen, maar alleen data in de vorm van getallen. Daar is weer een apart plekje voor (de CIR of de MAR).
Naast deze registers met een specifiek doel, bevatten een behoorlijk aantal architecturen ook nog General Purpose Registers. Dit zijn registers, die gebruikt worden om tijdelijk resultaten op te slaan, zonder dat ze een specifieke betekenis hebben. Bijvoorbeeld tussenresultaten van een berekening kun je hierin opslaan.
Waarschuwing
Let op! Met het Engelse woord ‘data’ in de naamgeving van MDR wordt hier dus specifiek data-getallen bedoeld. In de rest van de tekst gebruiken we het woord data om aan te geven dat het nog geïnterpreteerd moet worden.
3.2.4. Kloksnelheid#
Zoals hierboven beschreven, haalt de processor steeds informatie op uit het werkgeheugen (fetch), de Control Unit leest deze informatie (decode) en de ALU voert de informatie uit (execute). Soms moet er ook nog informatie terug in het werkgeheugen geschreven worden (store). Dit riedeltje herhaalt zich keer op keer en wordt ook wel de fetch-execute cycle genoemd.
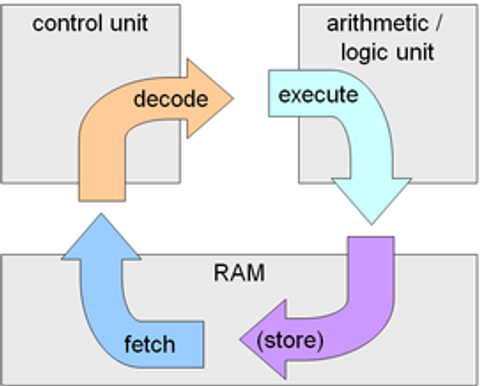
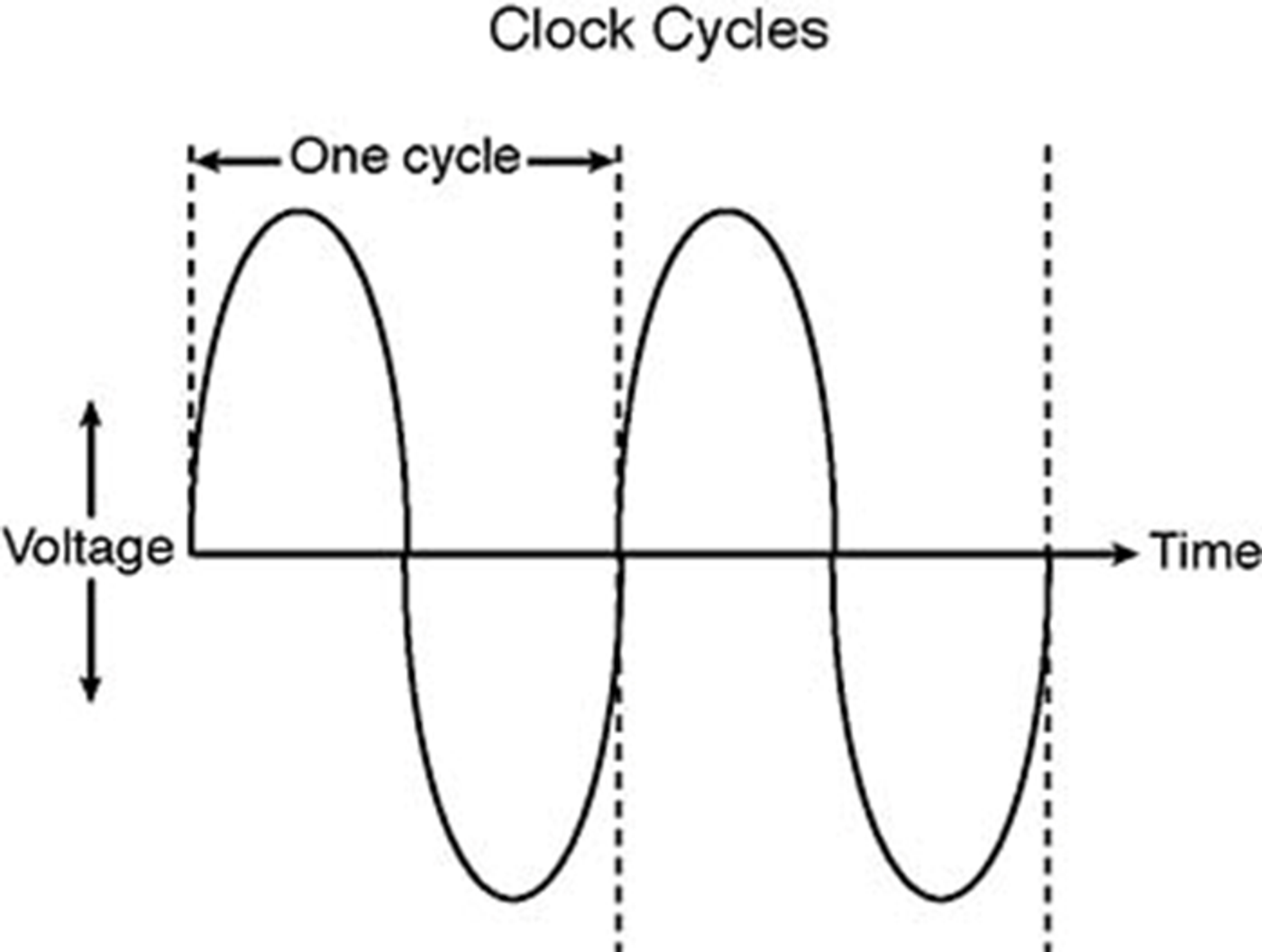
Die cyclus gaat met een vast patroon, maar ook met een vaste frequentie, als het ritme van een drum. Elke drumslag geeft het moment aan dat een nieuwe ronde van de cyclus gestart wordt. Dit noemen we de kloksnelheid en deze wordt uitgedrukt in Hertz. Hertz ken je waarschijnlijk ook van Natuurkunde als de frequentie van een golf. 1 Hertz is gelijk aan 1 instructie per seconde. De kloksnelheid is dus het aantal instructies dat de processor per seconde uit kan voeren uitgedrukt in Hz.
Die ene instructie per seconde is alleen best wel inefficiënt. Zoals je hierboven in de afbeelding ziet gebeurt elk onderdeeltje van een instructie namelijk ergens anders, werkgeheugen, control unit, of ALU. Nu kunnen alle onderdelen op elkaar blijven wachten, maar dan zitten ze een groot deel van de tijd nutteloos te zijn. Het is veel efficiënter als de instructies zich sneller achter elkaar opvolgen. Terwijl de control unit de ene instructie decodeert, is het werkgeheugen alvast bezig de volgende instructie op te halen en staat deze meteen klaar zodra de control unit klaar is. Dit noemen we pipelining. Op deze manier passen de instructies beter opvolgend aan elkaar, zoals ook in de afbeelding te zien is.
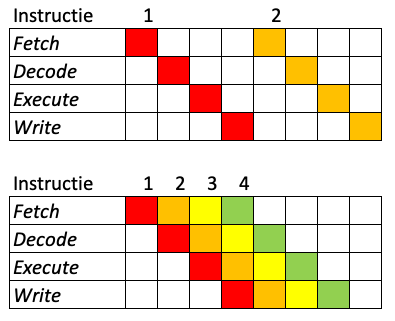
Notitie
Let op! Ook bij pipeling wordt er bij 1 Hz nog steeds maar één instructie per seconde voltooit, ook al zijn er wel meerdere instructies tegelijk in uitvoering.
3.2.5. Cores#
Toch kan er nog steeds maar een enkele instructie per cyclus voltooid worden, ook met pipelining. Om processors nog sneller te maken worden ze tegenwoordig opgedeeld in cores. Iedere core kan afzonderlijk een instructie uitvoeren. Op die manier is het mogelijk om meerdere instructies tegelijk te voltooien. Een enkele core met een snelheid van 1Hz kan dus 1 instructie per seconde voltooien, maar vier cores met ieder een snelheid van 1Hz kunnen dan vier instructies per seconde voltooien.
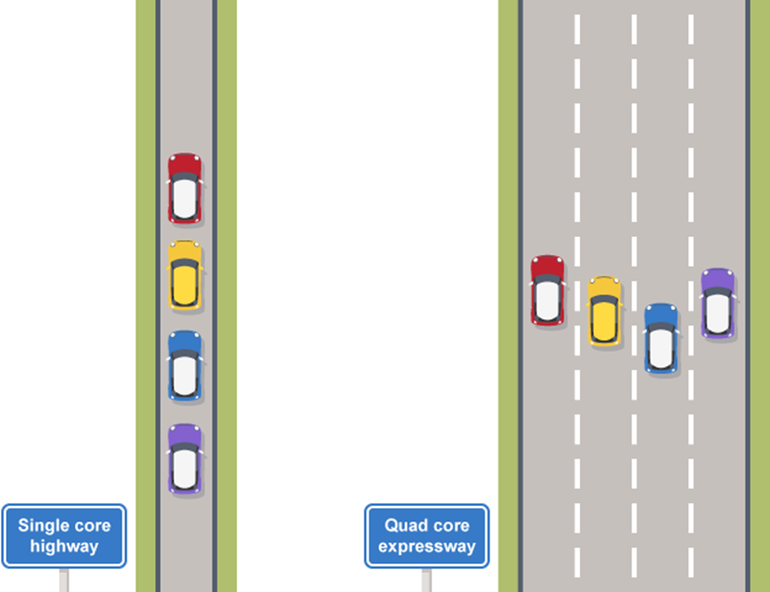
Je computer wordt een stuk beter in multitasken met meerdere cores, maar wordt daar niet perse altijd sneller van. Er kunnen meerdere taken parallel aan elkaar uitgevoerd worden, zoals het runnen van verschillende programma’s, maar een specifieke enkele taak gaat dan nog niet vlotter. Denk maar aan de uitspraak: “Een vrouw kan een baby maken in negen maanden, maar negen vrouwen kunnen niet samen in één maand een baby maken.”
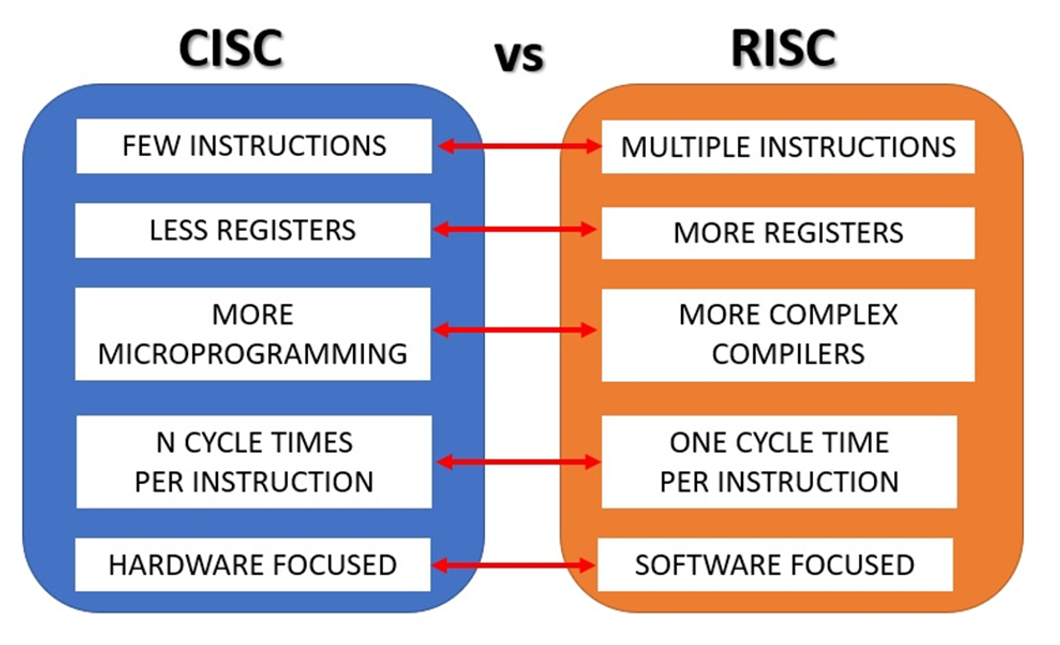
3.2.6. CISC & RISC#
De bovenstaande uitleg is alleen niet toepasbaar op iedere soort processor. Er zijn namelijk twee categorieën processoren: CISC en RISC. De uitleg hieronder is zwart of wit.
CISC staat voor Complex Instruction Set Computer. Deze categorie ken je van van laptops en PC’s met een Intel of AMD processor. Kenmerkend van CISC is dat er een hoop verschillende instructies zijn. Die instructies zijn behoorlijk complex (vandaar ook de naam). Complexe instructiesets zorgen ervoor dat programma’s zo compact mogelijk gemaakt kunnen worden. Omdat er veel verschillende instructies mogelijk zijn kan je met weinig achtereenvolgende instructies een heel programma schrijven. Je kan bijvoorbeeld met een enkele instructie twee getallen die in het werkgeheugen staan bij elkaar optellen. Op deze manier kunnen er compactere computerprogramma’s geschreven worden die weinig opslagruimte nodig hebben en dat scheelde tijd en geld.
Het idee van deze uitgebreide instructiesets klinkt onnodig ingewikkeld, maar deze is ontstaan omdat werkgeheugen vroeger erg duur en traag was. Computerbouwers streefden ernaar zo min mogelijk duur werkgeheugen nodig te hebben. Ook is het ophalen van data uit het werkgeheugen een van de traagste stappen in het proces dus hoe minder vaak er losse instructies uit het werkgeheugen opgehaald moeten worden hoe beter.
Een nadeel hiervan is dat de complexe instructies ingewikkelder zijn om uit te voeren. Zo ingewikkeld zelfs, dat ze soms niet in één klokcyclus uit te voeren zijn. Hoeveel tijd er dan wel nodig is om een instructie uit te voeren varieert. Dit maakt dat pipelining voor een CISC processor niet tot nauwelijks mogelijk is. Als de tijd die nodig is voor een instructie niet altijd in één klokcyclus past weet je niet of de onderdelen op tijd klaar zijn voor hun volgende taakje totdat de gehele instructie afgerond is. Geduldig afwachten tot het einde van de instructie dus.
De complexe instructies van een CISC-processor vereisen ook meer logische poorten. Dus meer transistoren, dus een hoger energieverbruik, dus meer warmte bij het gebruik van zo’n processor. Een voorbeeld van CISC-achtige processoren is de Intel i3/i5/i7/i9-serie. Waarschijnlijk zit een processor van deze ‘familie’ in je laptop. Deze processoren staan erom bekend niet echt energiezuinig te zijn en veel warmte te produceren. Vandaar alle aandacht voor de koeling.
Bij een CISC architectuur is er dus meer aandacht nodig voor de hardware om compactere software mogelijk te maken.
RISC processoren werken echter met Reduced Instruction Set Computer. Een voorbeeld is de ARM processor in je smartphone, tablet, en slimme apparaten. Sinds de opkomst van deze draagbare slimme apparaten is energiebeheer een stuk belangrijker geworden, en CISC is nou niet bepaald energiezuinig. Door een beperktere instructieset met minder mogelijkheden aan te bieden kunnen programma’s uitgevoerd worden op simpelere processoren die minder energie verbruiken. Maar dit maakt wel dat er meer moeite nodig is om programma’s te schrijven.
Waar bij CISC voor het optellen misschien maar een instructie nodig is, zijn daar bij RISC meer instructies voor nodig. Eerst twee keer een instructie om getallen uit het werkgeheugen op te halen en in een register te zetten, dan een instructie om de twee getallen vanuit het register bij elkaar in de accumulator op te tellen, en dan nog eentje om deze weer terug te schrijven naar het werkgeheugen. Programma’s geschreven voor een RISC instructieset zijn daarom ook groter dan hetzelfde programma geschreven in een CISC instructieset.
De compactere hardware vraagt om meer aandacht voor de software. Al die losse instructies maken wel dat deze categorie processoren over het algemeen een stukje trager is. Gelukkig passen bij RISC de instructies wél allemaal binnen een vaste klokcyclus. Daardoor kunnen RISC processoren wel gebruik maken van pipelining. Dat scheelt weer iets om het verschil in snelheid wat te compenseren.
3.2.7. Welke processor#
Nu weet je hoe processoren werken, maar hoe kom je er nou achter welke processor er in jouw computer zit? De drie grootste spelers die processoren produceren zijn Intel, AMD, en ARM. Intel en AMD zijn meestal CISC en worden gebruikt voor laptops en PC’s. Een apparaat waar geen Intel of AMD processor in zit heeft waarschijnlijk een ARM processor (RISC).
Er zijn verschillende manieren om op te zoeken wat voor processor er in een laptop of PC zit. Zo is het meestal wel mogelijk om met het modelnummer van de computer op het internet de specificaties op te zoeken. (Dat modelnummer staat bij laptops trouwens meestal op de onderkant.) Het is ook mogelijk dit in de computer zelf op te zoeken door middel van het programma Systeeminformatie of Taakbeheer. Taakbeheer is daarnaast extra interessant omdat deze ook de informatie over de belasting van de processor geeft. Ook zijn er speciale programma’s te downloaden die de specificaties van je computer kunnen uitlezen zoals CPU-Z of Speccy.
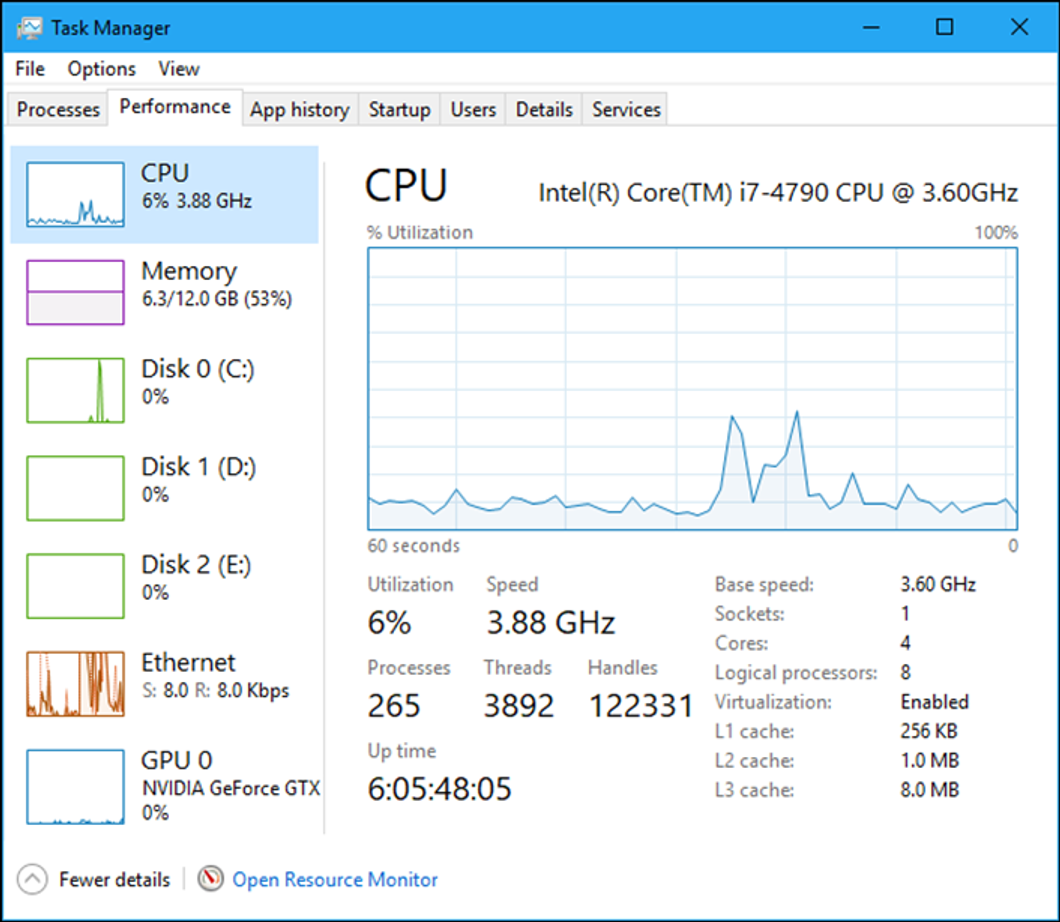
Fig. 3.8 Windows Taakbeheer#
Oefening 3.2
1a. Zoek met behulp van je taakbeheer op welke processor er in jouw computer zit en schrijf dat op.
1b. Denk je dat dit een krachtige processor is? Waarom wel/niet? Leg je antwoord uit.
1c. Benoem een voordeel en een nadeel van het hebben een krachtigere processor in je computer.
Soms kan je je computer sneller maken met overklokken. Wat gebeurt er dan met je processor? Benoem ook een nadeel van overklokken.
Wat is het effect op de processor wanneer je meerdere programma’s tegelijk aan het runnen bent?
Processoren worden snel warm. Benoem 3 verschillende technieken die toegepast worden om processoren te koelen. Geeft van iedere techniek aan hoe deze werkt en wat een voordeel en een nadeel is.
Er is veel discussie over het einde van de wet van Moore. Zal de wet van Moore voor altijd gelden? Leg je antwoord uit.
Beredeneer waarom een processor aparte opslagplaatsen heeft voor CIR, MAR en MDR
3.3. Geheugen#
3.3.1. Korte-termijn geheugen#
Een computer heeft naast een verwerkingsmodule (de processor) ook een geheugenmodule nodig. Tegenwoordig zijn er twee soorten geheugen te onderscheiden in een computer: het korte-termijn geheugen en het lange-termijn geheugen.

Fig. 3.9 Lange termijn geheugen#
Het lange-termijn geheugen slaat informatie voor langere tijd op, ook als de computer uit is geweest. Dit is bijvoorbeeld een harde schijf (HDD) of een Solid State Drive (SSD). Je slaat hier bestanden op zoals documenten, filmpjes, en geluid, maar ook programma’s worden bewaard op het lange-termijn geheugen. De grootte van je harde schijf of SSD wordt met gigabytes uitgedrukt, bijvoorbeeld 512 GB. Daar is veel opslagruimte nodig omdat deze informatie voor langere tijd bewaard moet worden en niet verdwijnt als de stroom wegvalt. Harde schijven en SSD’s zijn dan ook voorbeelden van niet-vluchtig geheugen.

Fig. 3.10 Korte termijn geheugen#
Het korte-termijn geheugen slaat informatie maar tijdelijk op. Je hebt vast wel eens van werkgeheugen gehoord, maar ook de registers van de processor zou je onder korte-termijn geheugen kunnen scharen. Dit hoofdstuk gaan we verder in op het werkgeheugen. De Engelse term hiervoor is Random Access Memory (RAM). De grootte van het werkgeheugen wordt net als een harde schijf of SSD ook uitgedrukt in gigabytes, maar is vaak een stuk kleiner in opslagcapaciteit. In plaats van 512 GB of zelfs 1 TB moet je dan eerder denken aan 16 of 32 GB. Het geheugen werkt met elektronische microchips en is bedoeld om informatie te bewaren voor programma’s die op dat moment actief zijn. Dit is vluchtig geheugen, dus wanneer de stroom wegvalt gaat de informatie in het geheugen verloren en ben je niet-opgeslagen informatie kwijt. Als je iets wilt bewaren moet je zorgen dat je op “opslaan” klikt zodat de informatie van het werkgeheugen naar je lange-termijn geheugen wordt verplaatst.
3.3.2. Random Access#
Wanneer je een bestand of programma opent wordt de bijbehorende informatie van de harde schijf of SSD naar het werkgeheugen verplaatst. Het werkgeheugen staat namelijk in directe verbinding met de processor en werkt een stuk sneller dan het lange-termijn geheugen. Dit is prettig wanneer je met een bestand of programma bezig bent, anders zou je computer heel traag functioneren. Vaak heb je meerdere bestanden en/of programma’s tegelijk open en wil je snel kunnen schakelen. Dat multitasken is niet zo vanzelfsprekend als het lijkt!

Fig. 3.11 Een cassettebandje#
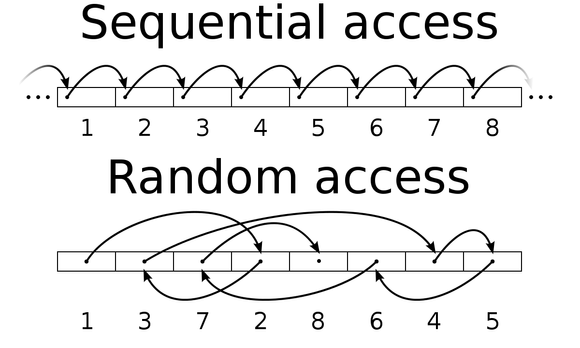
Om uit te leggen waarom dat bijzonder is springen we even terug in de tijd. Weet je misschien nog wat een cassettebandje is? Daar luisterden we vroeger muziek op, maar cassettebandjes werden ook gebruikt om informatie voor de computer op te bewaren. Het nadeel van deze tapes is dat als je een stukje informatie ergens verderop het bandje nodig had dat je eerst langs de rest van het bandje moest gaan om er te komen. Wilde je het vijfde liedje van een album horen? Dan moest je toch echt eerst de andere nummers afspelen. Er was namelijk een vaste volgorde. Dit heet sequentieel geheugen. Moet je je voorstellen dat dat ook voor jouw computer zou gelden. Dan probeer jij van Word te wisselen naar het derde tabblad in Google Chrome, maar gaat je computer eerst nog alle andere programma’s en eerdere tabbladen langs. Irritant!
Gelukkig werkt werkgeheugen niet op die manier. Werkgeheugen bestaat uit allemaal individuele opslagvakjes. Die vakjes bewaren informatie, en ze kunnen in iedere volgorde gelezen en aangepast worden. Je kan dus een specifiek vakje uitlezen zonder eerst de voorliggende vakjes door te moeten. Je kan opslagvakjes dan in willekeurige volgorde benaderen. Vandaar de term Random Access Memory (RAM).
3.3.3. Hiërarchie#
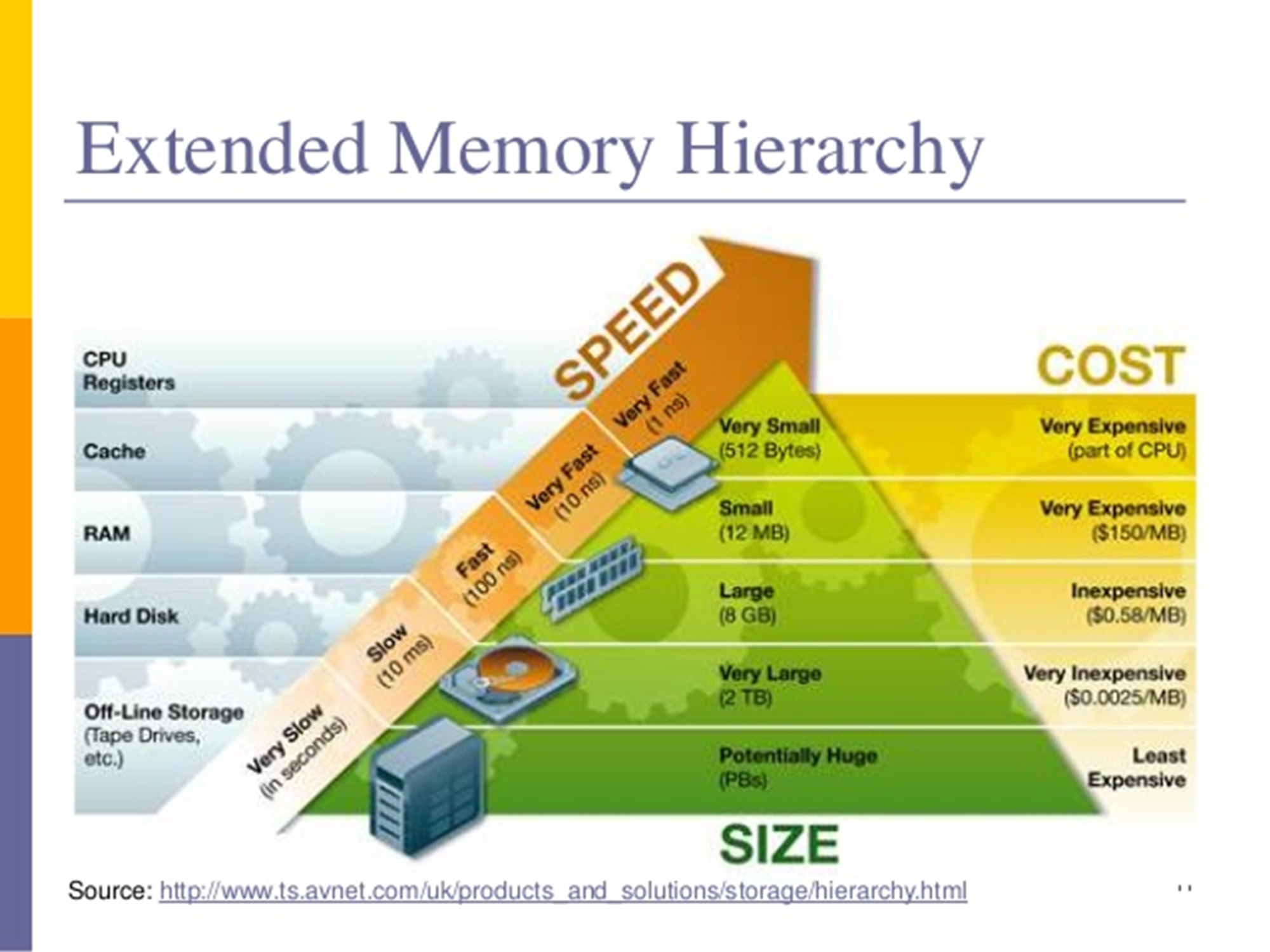
We hebben net al een aantal vormen van opslag voorbij horen komen, waaronder het geheugen, de harde schijf, en tapes. Deze vormen van opslag worden meestal omschreven aan de hand van drie eigenschappen: snelheid, grootte, en kosten. Zo heb je inmiddels geleerd dat een harde schijf langzamer is dan het geheugen, maar wel meer opslagcapaciteit heeft. Het is mogelijk om verschillende vormen van opslag in te delen met behulp van deze eigenschappen. Het resultaat zie je in de bovenstaande piramide voor de geheugenhiërarchie.
Tip
Bekijk ook de video “How computer memory works - Kanawat Senanan” van TED-Ed (Nederlandse ondertiteling)
3.3.4. Adressen en waardes#
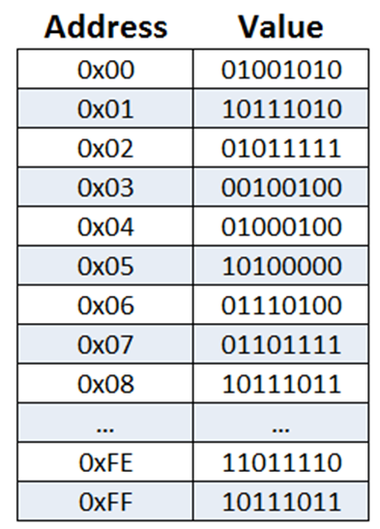
Werkgeheugen bestaat uit opslagvakjes waar informatie bewaard wordt. Ieder vakje heeft een adres en een waarde. Het adres is het nummer van het vakje zelf, de waarde is de informatie die in het vakje opgeslagen staat.
Adressen en waardes hebben een vaste lengte. Dit heet een “word”. Bij een 32-bits architectuur is dat een lengte van 32 bits. Bij 64-bits architecturen is dat een lengte van 64 bits. Dit betekent wel dat het vakje misschien groter is dan nodig. Een te groot vakje is gelukkig geen probleem. Een te klein vakje daarentegen is niet mogelijk.
De waarde van een vakje is de opgeslagen informatie. Dit kan gewoon een getal zijn, maar meestal is het iets meer dan dat. De waarde bestaat dan uit een combinatie van twee stukken: een instructie en een doeladres. De instructie is iets wat uitgevoerd moet worden door de processor. Bijvoorbeeld optellen, van elkaar af halen, of naar een ander opslagvakje springen. De processor voert deze instructie uit en leest of schrijft de bijbehorende informatie in het opslagvakje wat in het doeladres benoemt wordt. Een waarde kan dus zijn: ‘getal 9’. Maar een waarde kan ook zijn: ‘tel het getal uit opslagvakje 118 op bij het getal in de accumulator’. Of: ‘ga voor de volgende instructie naar opslagvakje 78 in plaats van het eerstvolgende postvakje’.
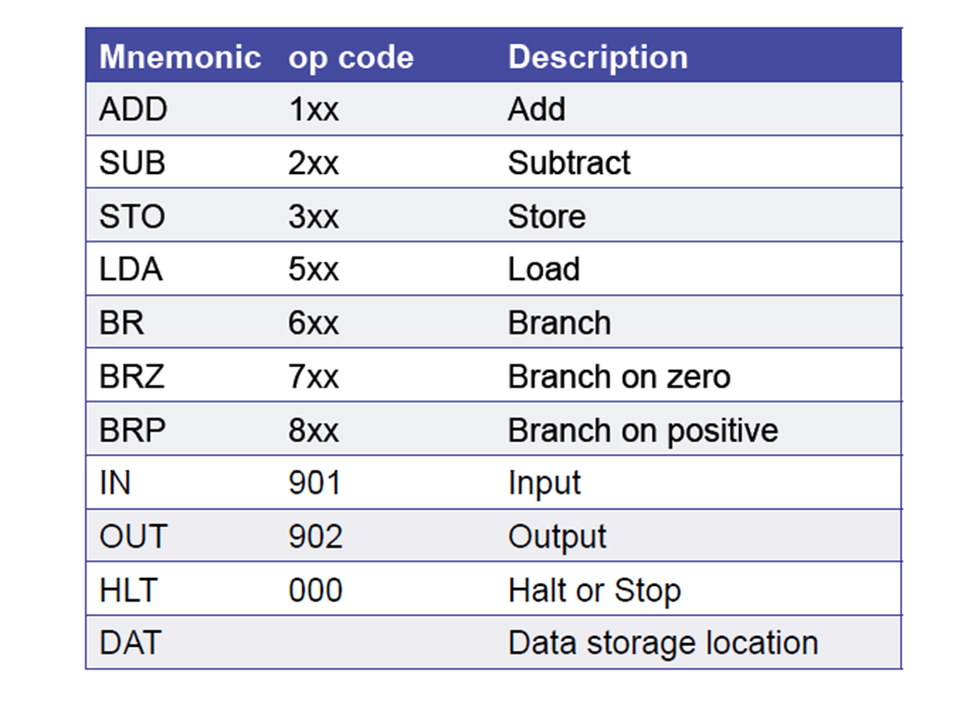
Fig. 3.12 Een voorbeeld van een versimpelde instructieset.#
Waarschuwing
Let op! Elke architectuur heeft zijn eigen instructieset. Dus een programma, geschreven voor een ARM-processor is niet geschikt voor een Intel-machine of voor je grafische rekenmachine TI-84.
3.3.5. Samenwerking met de processor#
Eigenlijk hebben het werkgeheugen en de processor niet een directe verbinding maar wel drie directe verbindingen. De drie verbindingen zijn: De adresbus, de databus, en de controlebus. Deze drie bussen zijn samen de systeembus die zorgt voor de verbinding tussen de processor en het werkgeheugen. Iedere bus heeft zijn eigen doel. De adresbus is aangesloten op het Memory Address Register van de processor, de databus is aangesloten op het Memory Data Register, en de controlebus is aangesloten op de Control Unit. Een enkele verbinding kan namelijk maar 1 stukje data tegelijk versturen. De verbinding tussen de processor en het werkgeheugen is een van de onderdelen die de snelheid erg beperkt. Het komt de snelheid ten goede als er stukjes informatie parallel aan elkaar gestuurd kunnen worden in plaats van achter elkaar aan. Door de systeembus op te delen in meerdere bussen wordt dit mogelijk gemaakt. Gelijktijdig drie keer 64 bits versturen is sneller dan 192 bits achter elkaar aan moeten versturen. Maar zelfs met deze drie aparte bussen blijft de verbinding tussen de processor en het werkgeheugen het traagste onderdeel. Dit betekent dat de processor vaak aan het niksen is terwijl die wacht tot de informatie van het werkgeheugen eindelijk aangekomen is zodat de processor dit kan verwerken. Dat wordt de Von Neumann Bottleneck genoemd.
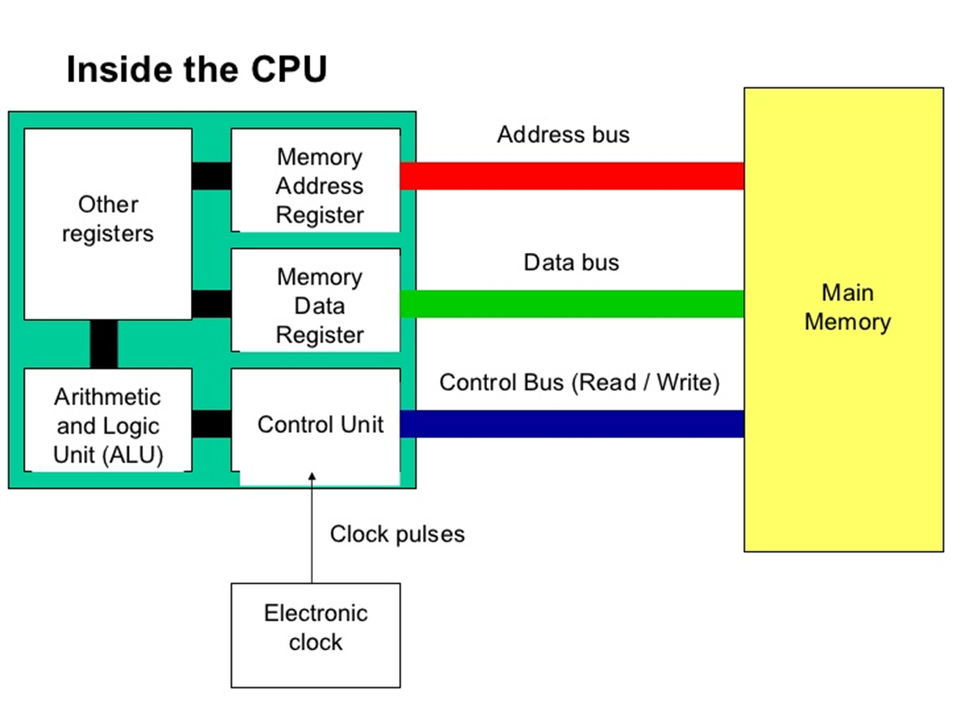
Fig. 3.13 Schema met adres-, data- en controlbus#
De Von Neumann Bottleneck is niet zo makkelijk op te lossen. Processorsnelheden worden met de jaren flink verbeterd, maar de snelheid voor het overdragen van informatie met de systeembus blijft achter in de technologische ontwikkelingen. Toch zijn er een aantal dingen die gedaan worden om de Von Neumann Bottleneck te omzeilen. Een voorbeeld daarvan is caching. Daarmee bevindt zich in de processor zelf nog een klein stukje geheugen die nóg sneller is dan het werkgeheugen. De meestgebruikte stukjes informatie worden ook in de cache bewaard zodat ze niet uit het werkgeheugen opgehaald hoeven toe worden maar meteen beschikbaar zijn voor de processor. Zoals je in de geheugenhiërarchie kan zien is cache nog sneller dan werkgeheugen maar ook duurder en kleiner in opslagcapaciteit. De geheugencapaciteit van de cache is dan ook veel kleiner dan van het werkgeheugen. Cache geheugen is ook weer onderverdeeld in 3 soorten:
L1 cache: het dichtst ‘tegen’ een core aan. Het snelst, bedoeld voor data en instructies. Meestal enkele kilobytes groot.
L2 cache: iets ‘verder’ van een core af, minder snel, alleen bedoeld voor data, meestal een grootte van enkele megabytes.
L3 cache: de verschillende cores van een processor delen deze cache. Deze cache wordt alleen gebruikt voor data en is meestal enkele megabytes groot, groter dan een L2 cache.
3.3.6. Snelheid#
Het werkgeheugen kan een merkbare impact hebben op de snelheid van je computer. Dit heeft onder andere te maken met de grootte van je werkgeheugen. Hoe meer opslagcapaciteit je werkgeheugen heeft hoe meer informatie er tegelijk actief open kan staan zonder al te veel snelheidsverlies. Met het programma Taakbeheer kan je zien hoeveel ruimte van je werkgeheugen in gebruik is en welke programma’s het meeste werkgeheugen in beslag nemen. Is je computer traag omdat al het werkgeheugen in gebruik is? Sluit dan de actieve programma’s die je op dat moment toch niet nodig hebt.
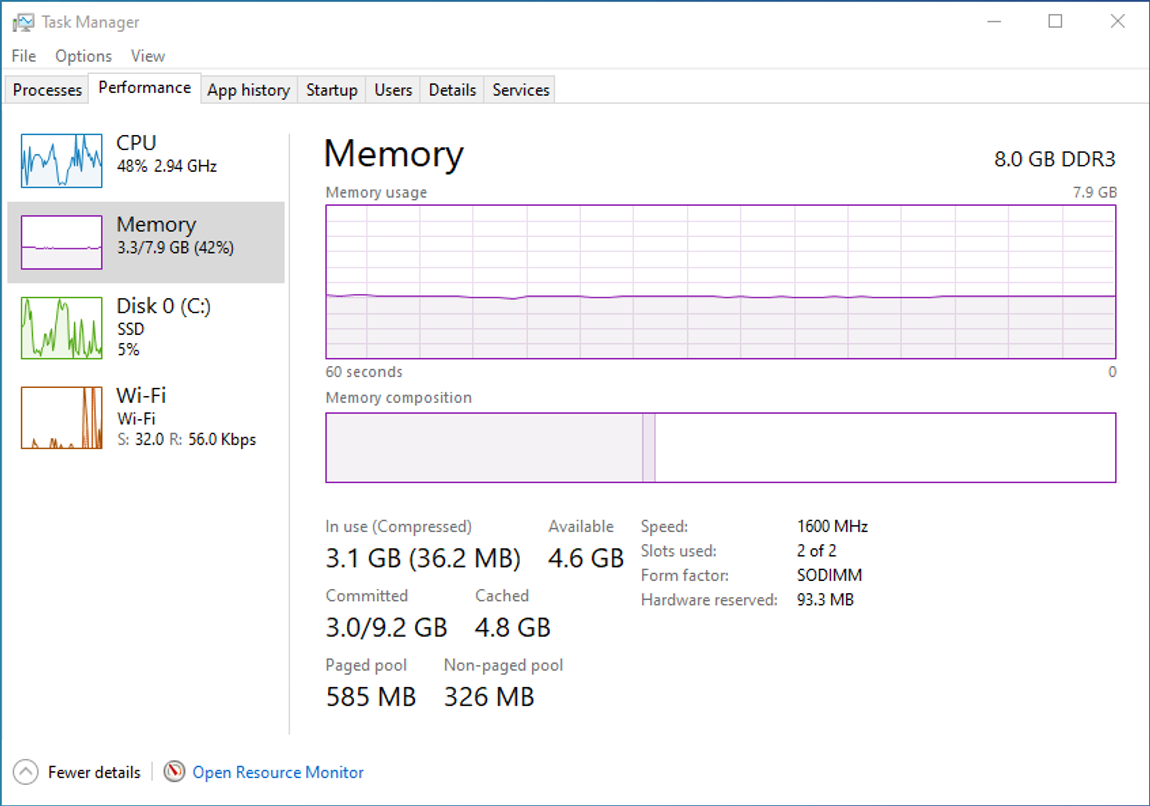
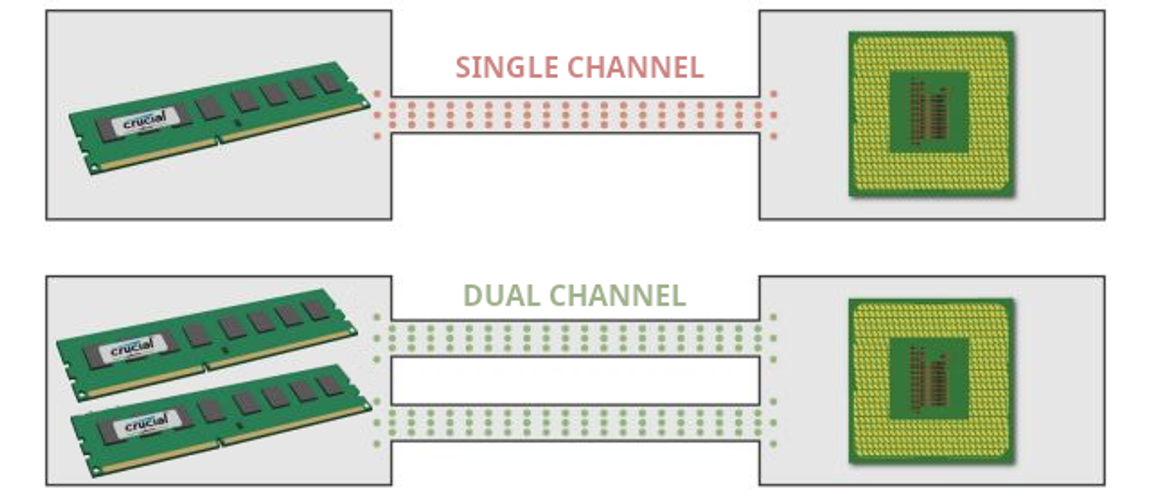
Wanneer je zelf je computer gaat bouwen zal je gegarandeerd op het punt komen waarbij je moet beslissen of je single channel of dual channel werkgeheugen wilt. Bij een single channel configuratie heb je een enkele werkgeheugenkaart van bijvoorbeeld 32 GB. Bij een dual channel configuratie heb je twee werkgeheugenkaarten, bijvoorbeeld twee kaarten van 16 GB. Dan heb je evenveel opslagcapaciteit voor je werkgeheugen, maar doordat je twee verbindingen hebt zou je meer informatie tegelijk kunnen uitwisselen met de processor. Dual channel zou dus sneller moeten zijn dan single channel, maar in de praktijk blijkt dit verschil niet meetbaar. De prijs zou nog wel een argument kunnen zijn. Het is vaak iets goedkoper om twee kaarten van 16 GB te kopen dan één van 32 GB.
Oefening 3.3
Waar valt de SSD in de geheugenhiërarchie? Leg je antwoord uit.
Als het werkgeheugen zoveel sneller is dan een harde schijf, waarom wordt dan niet alles opgeslagen in het werkgeheugen? Leg je antwoord uit aan de hand van de geheugenhiërarchie.
Er zijn nog meer eigenschappen van verschillende soorten geheugen die mogelijk meegenomen zou kunnen worden in de geheugenhiërarchie. Benoem een van deze eigenschappen en orden de verschillende geheugensoorten volgens de door jou gekozen eigenschap.
De 32-bits architectuur is ouder dan de 64-bits architectuur. Waarom is de 64-bits architectuur ontwikkeld? Wat had dit voor toegevoegde waarde?
Wat is het effect op je werkgeheugen wanneer je meerdere programma’s tegelijk aan het runnen bent?
Wat gebeurt er wanneer je meer programma’s tegelijk wilt runnen dan dat je ruimte in je werkgeheugen hebt?
Is een harde schijf Sequential Access Memory (SAM) of Random Access Memory (RAM)? Leg je antwoord uit.
Een cache heeft heel weinig opslagruimte en moet dus regelmatig opgeschoond worden. Er kan natuurlijk een willekeurig stuk cache geleegd worden om ruimte te maken, maar er zijn nog andere strategieën om te bepalen welke bewaarde informatie uit te cache wordt verwijderd. Bedenk drie verschillende strategieën voor het opschonen van de cache of zoek ze op het internet.
Open je taakbeheer en kijk bij de processen welke programma’s het meeste werkgeheugen gebruiken. Open eventueel nog wat extra programma’s als je niet zo veel open hebt staan. Welke programma’s hebben een hoge belasting op het werkgeheugen? Had je dat verwacht of verrast dit je?