Databases en SQL#
In deze module ga je leren hoe je informatie gestructureerd opslaat in databases. Je leert een deel van de databasetaal SQL (Structured Query Language) . Ook leer je hoe we een relationele database structuur ontwerpen . Tenslotte krijg je een beeld van andere soorten databases, samengevat onder de noemer ‘noSQL’.
0. Inleveropdrachten#
Welkom bij een informaticamodule van de Q-highschool!
Deze module werkt met een inleveropdracht, die voor deadline moet zijn ingeleverd. ``
Deadline#
Laatste week van het “blok” (bij een vier-blokken-per-jaar rooster). De docent vertelt je de deadline voor het blok bij elke les. Eerder inleveren mag.
Inleveren via: https://app.q-highschool.nl/
Zelfstandig werken en bronnen vermelden#
De volgende uitgangspunten gelden voor deze module:
Je maakt de opdracht zelf
Als je iets overneemt van een boek of internet, doe je dat met bronvermelding
Je werk is overzichtelijk en netjes
Opdrachten met broncode#
Informatica heeft vaak opdrachten met broncode, vormen van programmeerwerk.
Je levert een bestand dat in voor computers en voor mensen leesbaar is
Let daarom goed op de instructies bij de opdracht
Meerdere bestanden inleveren#
Maak een mapje met daarin de bestanden
Maak van dat mapje een zip-bestand
Lever het zip-bestand in via: https://app.q-highschool.nl/
1. Wat is een database?#
Laten we om te beginnen eens te kijken naar een aantal voorbeelden van databases.
Je school moet vanalles van jou bijhouden. Heb je je wel eens afgevraagd hoe de computer jouw cijferadministratie bijhoudt? Hoe weet die computer dat die 7,3 bij jouw Aardrijkskunde proefwerk hoort? En hoe houdt de computer bij dat jij bij die les Frans aanwezig was? De invoer hiervan gebeurt uiteraard door mensen, de opslag vindt plaats in een gestructureerd informatiesysteem, een database.
Een ander voorbeeld van een database zie je bij sociale netwerken zoals Instagram. Hoe bewaart Insta wie jouw volgers zijn en wie jij volgt? Hoe houdt Insta bij dat die foto bij jou hoort en niet bij het Insta-account van iemand anders. Precies, dat wordt bijgehouden in een grote database. Een netwerk van vriendschappen vereist een wezenlijk andere database dan “saaie” gegevens over cijfers. De hoeveelheid gegevens in een groot sociaal netwerk vereist dat er goed wordt nagedacht over efficientie.
Kortom, een database is een grote bak met gestructureerde informatie, die digitaal opgeslagen is in een computer. In de informatica noemen we een database ook wel eens informatiesysteem. Er zijn verschillende typen databases. In deze module gaan we vooral aan de slag met relationele databases. Bij dit type database wordt de informatie opgeslagen in tabellen met rijen en kolommen.
Andere types database worden vaak samengevat onder de noemer “noSQL”, voorbeelden daarvan komen ook aan bod.
2. Data uit een informatiesysteem halen#
SQL: structured query language: gestructureerde vraag-taal.
Voordat we gaan kijken hoe een relationele database tot stand komt, gaan we eerst leren vragen te stellen aan zo’n database. Al in de jaren tachtig van de vorige eeuw is een standaard ontstaan om vragen te stellen aan dit type database, SQL. SQL staat voor structured query language, een gestructureerde manier om vragen te stellen aan een database. Dat is zo’n goed idee gebleken dat het nog steeds overal wordt toegepast!
Met SQL kun je zowel vragen stellen aan een database over de gegevens die er in zitten, maar ook het bewerken van informatie en de structuur van de database werkt via SQL. In dit hoofdstuk ga je leren queries (vragen) in SQL te schrijven.
De inleveropdracht en kennismaking met en lesmateriaal over relationele databases met SQL vind je op deze speciale website. Gemaakt door docent Merijn.
3. Een informatiesysteem ontwerpen#
In dit hoofdstuk leer je de rollen binnen informatie-analyse en wat er komt kijken bij het ontwerpen van een database.
Bij het ontwikkelen van een informatiesysteem kan men drie fasen onderscheiden:
Analyse
Ontwerp
Realisatie
3.1 Analyse: welke informatie is er#
Om een informatiesysteem te kunnen ontwerpen moet je gesprekken voeren met de klant waarin deze zijn/haar wensen kenbaar kan maken. Dat is lastiger dan het lijkt, want de klant heeft er vaak geen idee van hoe een database werkt. Twee dingen zijn hierbij belangrijk:
Stel de juiste vragen aan de klant
Stel ook de vragen, waar de klant niet aan denkt
De rol die hierbij hoort heet informatie-analist. Als je de project informatica modules hebt gedaan weet je dat dit werk vaak bij de product owner terechtkomt. Bij erg complexe structuren of bij grote projecten is het soms een aparte rol. Het is de brug tussen de business en de techniek: de business zijn de mensen die weten hoe een bedrijf geld verdient, de techniek zijn de mensen die dat tot werkelijkheid moeten maken.
Het kan zijn dat het eerst goed is processen van een bedrijf in kaart te brengen en in domeinen onder te brengen. Dit heet ‘domain driven design’. Vooral grotere klanten kunnen er baat bij hebben inzicht te krijgen en geven in processen, zeker als die hele afdelingen overstijgen. Het kan binnen een bedrijf zo zijn dat de ene afdeling een andere naam heeft voor hetzelfde ding als een andere! De rol die hierbij hoort is de proces-analist.
3.2 Ontwerp: structuur aanbrengen in de informatie#
Een informatie-analyst maakt op basis van het contact met de klant een model van het informatiesysteem. Dit zogehegen entiteit-relatie-model (ERM) heeft de vorm van een entiteit-relatie diagram (ERD).
Entiteiten zijn de ‘dingen’ die je wil opslaan. Bij een apotheek denk je bijvoorbeeld aan patienten, medicijnen, recepten en de verstrekking van medicijnen. In het voorgaande voorbeeld is een ‘verstrekking’ het afgeven van een medicijn aan een patient, bij de balie van een apotheek. Er is een verband tussen de verstrekking, een recept, een medicijn en een patient.
ERD: entiteit relatie diagram. Dit diagram geeft weer welke entiteiten (dingen) er worden opgeslagen en hoe ze aan elkaar gekoppeld zijn.
3.3 De bouw#
Wanneer je een ontwerp gemaakt hebt is het zaak om hier een technische invulling aan te geven.
De database is slechts een enkele schakel in de keten. Vaak zie je een zogeheten drielaags opzet:
frond-end: een webpagina of app die de gebruiker ziet
middleware: een programma dat gegevens ontvangt, controleert en opslaat in een database. En ook gegevens stuurt naar de front-end.
database: de opslag van de gegevens. De database wordt vanuit de middlware bestuurd via SQL.
De middleware bevat logica, de spelregels. Onder andere zorgt dat er voor dat gegevens in de database alleen zichtbaar zijn voor wie erbij mag. Ook kan de middleware gegevens uit meerdere tabellen bij elkaar brengen. De front-end is puur voor het laten zien van gegevens en eventueel bewerken.
3.4 Entiteiten, attributen en waarden#
Bij het ophalen van gegevens uit de database, in hoofdstuk twee, heb je geleerd dat gegevens zijn opgeslagen in tabellen, met rijen en kolommen. Tabellen, rijen en kolommen zijn termen voor de “fysieke” database. Bij het ontwerpen van databases
Een logisch ontwerp bestaat uit entiteiten en attributen.
Een entiteit is het object waarvan de informatie wordt opgeslagen
Een attribuut is een eigenschap van een entiteit.
De entiteiten en attributen, die voorkomen in een logisch ontwerp, vertalen zich in een fysiek ontwerp naar tabellen en kolomnamen

Leerling |
|||
|---|---|---|---|
voornaam |
achternaam |
geboortedatum |
telefoonnr |
Piet |
Konijn |
13-4-2012 |
0611211211 |
Jan |
Haas |
15-2-2012 |
|
Sylvia |
Slak |
23-7-2011 |
0600700700 |
In het voorbeeld hierboven is een leerling een entiteit en geboortedatum een attribuut. Wanneer je de database gaat bouwen, vul je de rijen van de tabellen met waarden (Engels: values). Konijn is dus een waarde. Een leeg vakje betekent dat er geen waarde is. Je noemt de waarde dan null. Deze waarde null is dus iets anders dan de waarde 0, want dat is wel een waarde. null is letterlijk de verwijzing naar niets. Geen waarde.
Wanneer je een entiteit tekent, moet je aan bepaalde regels voldoen:
Gebruik rechthoeken met afgeronde hoeken
De entiteitnaam moet in hoofdletters en enkelvoud
De attribuutnamen moeten in kleine letters
Hieronder staat een voorbeeld van een fysiek ontwerp van de tabel leerlingen. Er zijn meer kolommen, die nodig zijn bij een ontwerp. Welke dat zijn komen verderop in deze module. Zoals je ziet wordt aan elke kolomnaam een datatype (format) toegevoegd.
Fysiek ontwerp van tabel leerlingen |
|||
|---|---|---|---|
kolomnaam |
datatype |
lengte |
standaardwaarde |
voornaam |
|
20 |
|
*achternaam |
|
30 |
|
geboortedatum |
|
||
tel_nr |
|
10 |
Het datatype is het soort dat wordt opgeslagen. Bij databases komen de soorten getal (bijvoorbeeld integer of real), string (varchar, char), datum (date), plaatje/geluid (blob) voor.
Bij het definiëren van een varchar moeten we altijd de lengte van dat tekstveld opgeven. Een tekstveld met lengte 50 geef je weer met varchar(50). Natuurlijk mag je ook kortere tekst opslaan in zo’n tekstveld. Het getal geeft de maximumlengte aan. Een char-veld van lengte 10 moet tekst van lengte 10 bevatten. Kortere teksten zijn bij zo’n type veld niet toegestaan.
Met de standaardwaarde bedoelen we dat er al standaard een waarde is ingevuld. Wanneer je bijvoorbeeld een kolomnaam “nationaliteit” hebt en bijna alle klanten hebben de Nederlandse nationaliteit, dan zou je hier “NL” als standaardwaarde kunnen invullen. Slechts enkele klanten hoeven dit veld dan aan te passen in hun formulier.
3.6 Soorten attributen#
Vluchtige attributen Niet alle eigenschappen zijn even geschikt om te gebruiken in een database. In bovenstaand voorbeeld zou je bijvoorbeeld de eigenschap ‘leeftijd’ kunnen gebruiken in plaats van ‘geboortedatum’. Dat is echter niet handig, want je zult dan na iedere verjaardag de leeftijd bij moeten werken. Zo’n veranderende eigenschap noemen we een vluchtig attribuut.
Verplicht of optioneel Sommige attributen moeten altijd worden ingevuld. In het voorbeeld hierboven is dat bijvoorbeeld ‘achternaam’. Dit zijn verplichte attributen. Andere zijn optioneel en dus niet verplicht. In het voorbeeld hierboven is dat bijvoorbeeld het telefoonnummer. Niet iedereeen heeft een telefoonnummer of wil dit in de database ingevoerd hebben.
UID Unieke identifier In een database wil je perse dat iedere rij uniek is. Geen enkele regel mag exact hetzelfde zijn. Om te garanderen dat dit het geval is, maakt men gebruik van unieke identifiers afgekort UID. Dit kan een attribuut zijn of combinatie van attributen. Zelfs een relatie kan deel uitmaken van een UID. In het voorbeeld hierboven kun je denken dat ‘achternaam’ een prima UID is. Op een school kunnen echter verschillende leerlingen met dezelfde achternaam zitten. Een betere UID zou de combinatie van voor- en achternaam kunnen zijn. Wanneer je school groot genoeg is, zullen er vanzelf leerlingen met dezelfde voor- en achternaam op die school zitten. Je zou de UID kunnen definiëren als de combinatie van voor-, achternaam en geboortedatum. Maar ja, hier kleven ook weer risico’s aan. Om alle risico’s uit te sluiten, kun je een extra attribuut toevoegen. In dit geval ‘leerlingnummer’. Door voor iedere leerling een nieuw nummer te gebruiken, is persoonsverwisseling uitgesloten.
In het fysieke model heet een UID de primary key of PK.
De entiteit LEERLING zou er dan als volgt uit kunnen zien:

In je ERD geef je deze attribuut-eigenschappen als volgt weer:
#= primary UID. Dit is de UID die uiteindelijk gebruikt gaat worden
(#) = secondary UID. Deze UID wordt als reserve en mogelijk als controlemiddel gebruik. Hier is dat de combinatie van voornaam, achternaam en geboortedatum.
*= een verplicht attribuut
o= een optioneel attribuut
3.7 Opdrachten#
Opdracht 3.7.1 Hieronder staat een verhaaltje. Met dit verhaaltje wil je een database ontwerpen. Geef aan welke woorden uit dit verhaaltje je als entiteit zou gebruiken, welke als eigenschap en welke als waarde? Noem ook de eigenschappen die niet in de tekst genoemd staan maar waarvan wel waarden zijn genoemd.
Bij autohandel “Krakkemik” staan er auto’s van verschillende merken op het terrein. Zo staat er een rode Opel Astra uit 1998 voor €1500, een groene Ford Escort uit 2002 voor €2000 en een Peugeot waarvan de prijs €4000 is.
Opdracht 3.7.2 Teken de entiteit die bij de opgave uit de vorige vraag hoort. Bedenk zelf de attributen, die niet in de tekst voorkomen. Geef aan welke attributen tot de UID behoren, welke verplicht zijn en welke optioneel.
Opdracht 3.7.3 Geef bij ieder attribuut uit de vorige opgave aan welk datatype en lengte je zou gebruiken in het fysieke model. Je kunt op deze site een lijst van datatypes vinden, die in SQL gebruikt worden.
Opdracht 3.7.4 Leg uit waarom in iemands paspoort niet diens haarlengte staat opgegeven.
4. Relaties#
Een entiteit in een informatiesysteem is, vanuit ons perspectief, niet zo interessant. Het vormt de basis voor een heel simpel lijstje. Daar heb je geen DBMS voor nodig. Het wordt pas echt interessant, wanneer er twee of meerdere entiteiten in het informatiesysteem voorkomen. Entiteiten kunnen dan een onderlinge relatie hebben. Een relatie:
geeft aan hoe entiteiten zich tot elkaar verhouden
heeft een richting. Dus van entiteit A naar entiteit B kan een andere relatie zijn dan van entiteit B naar entiteit A.
hebben een mate van kardinaliteit. Kardinaliteit zegt iets over de hoeveelheid informatie in die specifieke relatie.
Dit netwerk van entiteiten en relaties is de basis van je logisch ontwerp.
4.1 Erdish#
Om vanuit de analyse-fase naar een logisch model te komen, zul je op een of andere manier de entiteiten en relaties tussen die entiteiten moeten zien te ontdekken. Één van die manieren is door relaties in het Erdisch op te schrijven. Dit is een gekunstelde taal, die je in staat stelt om relaties precies uit te drukken.
Voorbeelden
Iedere werknemer heeft één of meer banen.
Iedere baan wordt door precies één werknemer vervuld.
Iedere klant koopt één of meer producten.
Ieder product wordt gekocht door nul of meer klanten.
Toelichting
Iedere zin begint met iedere of elke.
De zinnen komen in paren.
Er zit een werkwoord in de zin.
“Één of meer”, “precies één”, “nul of één” en “nul of meer” geven de kardinaliteit aan.
Het onderwerp en lijdend voorwerp in de zin wordt gevormd door entiteiten
Vaak moet met de opdrachtgever besproken worden hoe het precies zit. Is het bijvoorbeeld toegestaan dat een werknemer meerdere banen heeft?
Tekenafspraken Er bestaan meerdere notaties, maar wij gebruiken de kraaienpoot notatie, omdat die het meest intuïtief is. Je mag de diagrammen met de hand tekenen. Wanneer je ze op de computer wil maken, dan kun je het gratis programma yEd Graph Editor gebruiken. Alle diagrammen in deze syllabus zijn met dat programma gemaakt.
De zinnen in het voorbeeld laten zich naar het volgende ERD omzetten. De zin ‘Iedere werknemer heeft één of meer banen’ lees je in het onderstaande diagram af van links naar rechts. De kardinaliteit van de relatie wordt aangegeven door die vorm, die op een slecht getekende letter K lijkt. De kardinaliteit zet je dus bij het lijdend voorwerp van de Erdisch zin.

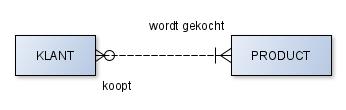
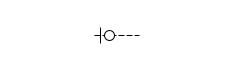
De vier kardinaliteiten worden in een diagram met de volgende kraaienpoten weergegeven:
Kardinaliteit |
De bijbehorende kraaienpoot |
|---|---|
Nul of één |
|
Precies één |
|
Nul of meer |
|
Één of meer |
|
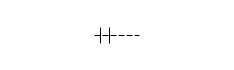
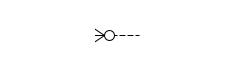
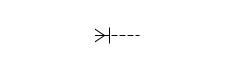
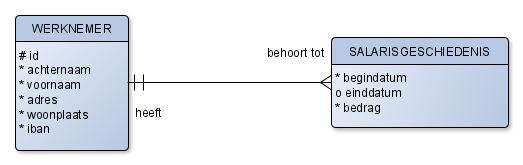
Tussen de entiteiten worden doorgaans onderbroken lijnen getrokken. Met een doorgetrokken of ononderbroken lijn geef je aan dat er een ouder-kind-relatie is. Hieronder staat een voorbeeld. De kind-entiteit erft hier het UID van de ouder-entiteit. Je kunt met deze notatie helaas niet zo snel zien wat de ouder-entiteit en wat de kind-entiteit is. Wanneer je iets dieper naar het diagram kijkt, zie dat er alleen een primary UID voor werknemer is gedefinieerd, dus dat is de ouder-entiteit en salarisgeschiedenis is de kind-entiteit. De doorgetrokken lijn geeft aan dat er een ouder-kind relatie is.
Je zult je nu afvragen: elke entiteit moet toch een UID hebben? Dat klopt. In het geval van salarisgeschiedenis is de UID werknemer_id. De UID voor deze entiteit bestaat dus niet uit een attribuut, maar uit een relatie! Belangrijk: in het fysieke model komt hiervoor een extra kolom werknemer_id in de tabel SALARISGESCHIEDENIS.
4.2 ERD#
De diagrammen, die we hierboven beschreven hebben, noemen we een ERD, een Entity Relationship Diagram. Je hebt tot nu alleen nog erg eenvoudige ERD’s gezien. Een ERD geeft de belangrijke entiteiten en hun relaties weer. Het doel van een ERD is om in de analyse en logische fase van het ontwerp een voorstel te documenteren, waarover met de opdrachtgever gediscussieerd kan worden.
Informatie mag slechts één keer worden getoond in een ERD. Daarnaast mag je geen informatie in het model stoppen, die kan worden afgeleid van andere informatie. Bijvoorbeeld wanneer je de geboortedatum van een persoon al hebt opgeslagen mag je niet nog eens de leeftijd van die persoon opslaan. De leeftijd kan namelijk aan de hand van de geboortedatum berekend worden.
Constraints Constraints zin beperkingen of voorwaarden, die voortvloeien uit de analyse van bedrijfsregels. Stel dat een bedrijf wil dat het informatiesysteem een seintje geeft als een werknemer 25 jaar bij het bedrijf werkt, zodat er iets georganiseerd kan worden, dan moet dit in de bouwfase in het informatiesysteem geprogrammeerd worden. Deze constraints zet je als losse informatie in je ERD.
Andere voorbeelden:
Er mogen geen geboortedata worden ingevoerd, die in de toekomst liggen.
Een begindatum moet voor een einddatum liggen.
Een afdeling moet uit minimaal drie werknemers bestaan.
Dit kun je voor elkaar krijgen door extra programmeerwerk. Afhankelijk van je DBMS is dit mogelijk in het DMBS zelf of zul je het in de applicatie zelf moeten uitprogrammeren.
Andere constraints zoals welke attributen tot de UID behoren kun je wel in de ERD opnemen.
Overdraagbaarheid Sommige relaties zijn niet overdraagbaar (transferable). Het komt alleen voor aan de “één”-kant van relaties met de kardinaliteit één-of-meer. Weet je nog welke kraaienpoot hierbij hoort? Niet overdraagbare relaties zul je wel in je ERD moeten noteren. In het fysieke model maak je vervolgens de relatie aan die kant niet aanpasbaar (not updatable). Bekijk het voorbeeld hieronder.
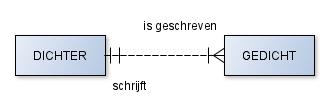
Een gedicht dat eenmaal door een bepaalde dichter is geschreven kan later niet door een andere dichter zijn geschreven. Er moeten maatregelen genomen worden zodat dit niet aangepast kan worden. De relatie van gediacht naar dichter is dus niet overdraagbaar. De relatie van dichter naar gedicht is wel overdraagbaar omdat de dichter meerdere gedichten heeft geschreven en hij dus het ene gedicht kan uitwisselen met het andere. Merk ook op dat de relatie van dichter naar gedicht aan de “meer”-kant van de kardinaliteit zit.
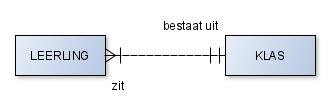
De relaties hierboven zijn beiden overdraagbaar want een leerling kan achteraf naar een andere klas worden overgeplaatst.
4.3 CRUD Analyse#
Een ERD zal uiteindelijk leiden tot een verzameling tabellen waarin we gegevens als rijen gaan opslaan (de database). Een database vormt de basis voor een bedrijfsapplicatie. Zo’n applicatie is opgebouwd uit verschillende modules. Een voorbeeld van zo’n module is ‘Adreswijziging leerling’ of ‘Cijferoverzicht’. Je kunt dan per module een zogenaamde CRUD-analyse als document aan je ERD toevoegen. Daarin wordt genoteerd welke data in die module wordt opgehaald, aangepast en verwijder moet kunnen worden.
Actie |
Betekenis |
|---|---|
Create |
Welke data wordt aangemaakt? |
Retrieve |
Welke data wordt opgehaald? |
Update |
Welke data wordt ververst? |
Delete |
Welke data wordt gewist? |
4.4 Opdrachten#
Opdracht 4.4.1 Erdish zinnen maken Maak steeds twee Erdish zinnen over de relaties tussen de twee entiteiten.
Leerling, Klas
Leerling, Stoel
Fototoestel, Foto
Gedicht, Dichter
Opdracht 4.4.2 ERD lezen
Schrijf de Erdisch zinnen op bij onderstaande relaties in het ERD. Let op de richting van de relaties!
Er staan een paar relaties tussen, die in werkelijkheid niet kloppen. Schrijf achter iedere zin of de relatie kan of niet kan.


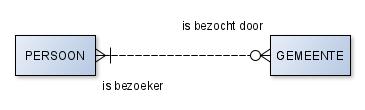

Opdracht 4.4.3 ERD tekenen Teken ERD’s bij de volgende relaties.
Iedere woonplaats is de geboorteplaats van nul of meer personen. Iedere persoon is geboren in precies één woonplaats.
Iedere kamer herbergt nul of meer gasten. Iedere gast logeert in precies één kamer.
Iedere werknemer werkt op precies één afdeling. Iedere afdeling heeft één of meer werknemers.
Iedere e-mail is gericht aan één of meer personen. Ieder persoon is de geadresseerde van nul of meer e-mails.
Ieder stuk gereedschap heeft precies één prijs. Iedere prijs hoort bij één of meer stukken gereedschap.
Ieder kind heeft precies één moeder. Iedere moeder heeft één of meer kinderen.
Iedere leerling heeft les van één of meer docenten. Iedere docent geeft les aan één of meer kinderen.
Iedere vingerafdruk behoort tot precies één persoon. Ieder persoon heeft één of meer vingerafdrukken.
Opdracht 4.4.4 Overdraagbaarheid Geef aan welke van de relaties uit de vorige opgave niet overdraagbaar zijn. Onderbouw je antwoord.
5. De weg naar een goede ERD#
Het komt vaak voor dat een ERD uit meer dan twee entiteiten zal bestaan. In de analyse komen er allerlei kandidaat entiteiten naar voren. Alleen entiteiten waartussen een relatie bestaat worden in de ERD opgenomen. Om deze entiteiten te kunnen vinden, kun je een matrix gebruiken. Een matrix helpt bij het vinden van mogelijke relaties tussen entiteiten. Hieronder staat een voorbeeld.
REIZIGER |
LAND |
BEZIENSWAARDIGHEID |
BETAALMIDDEL |
|
|---|---|---|---|---|
REIZIGER |
x |
bezoekt |
wordt bezocht |
betaalt met |
LAND |
wordt bezocht |
x |
bezit |
x |
BEZIENSWAARDIGHEID |
wordt bezocht |
ligt in |
x |
wordt betaald met |
BETAALMIDDEL |
wordt gebruikt |
x |
wordt gebruikt |
x |
Nadat je alle entiteiten, attributen en relaties bepaald hebt, is er een grote kans dat je onvolkomenheden in je ERD hebt zitten. De theorie die hierachter zit heet ‘normalisatie’. Dat is een heel technische term, in dit hoofdstuk bespreken we wat de concrete problemen zijn en oplossingen welke zijn daarbij horen.
Probleem 1: Redundantie, meer van hetzelfde#
Bekijk de volgende tabel
leerling nummer |
voornaam |
vak |
dag |
tijd |
lokaal |
docent |
|---|---|---|---|---|---|---|
174 |
Robin |
informatica |
maandag |
8:30 |
42 |
Pieter |
175 |
Isa |
informatica |
maandag |
8:30 |
42 |
Pieter |
176 |
Jamie |
informatica |
maandag |
8:30 |
42 |
Pieter |
174 |
Robin |
filosofie |
maandag |
9:30 |
33 |
Merijn |
176 |
Isa |
filosofie |
maandag |
9:30 |
33 |
Merijn |
Wat valt er op? Er staat veel dubbele informatie in. Dat noemen we ‘redundantie’. Het is onduidelijk wat de entiteit hier is, het zijn er feitelijk meerdere door elkaar.
Als je een model maakt en je merkt dat je gegevens vaak terug ziet komen, dan betekent dat meestal dat je een entiteit moet opbreken.
Als de tabel hierboven een schoolrooster voorstelt dan zou het model moeten bestaan uit meerdere entiteiten:
Leerling, met leerling nummer, naam en andere nodige gegevens
Vak, met de naam van de vakken en een relatie met de bijhorende docenten
Docent, met naam en andere gegevens per docent
Rooster dat alles aan elkaar koppelt.
We gaan in de klas oefenen met het maken van een model voor klassen, vakken, docenten en uiteindelijk rooster.
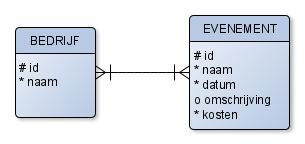
Probleem 2: Meer-meer relaties#
Wanneer je een ERD maakt, kom je vaak meer-meer relaties tegen. Dat zijn relaties waarbij de kardinaliteit in beide richtingen van de relatie het sleutelwoord ‘meer’ bevat. Relationele databases kunnen hier niet mee omgaan. De oplossing is het maken van een een tussenentiteit, in de database wordt dat een ‘koppeltabel’.
Voorbeeld
Oplossing
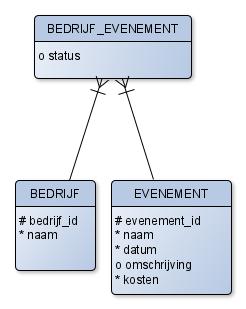
Je ziet dat de meer-meer relatie nu is verdwenen. De lijnen zijn doorgetrokken. Dat betekent dat de UID van BEDRIJF_EVENEMENT een combinatie is van bedrijf_id en evenement_id. De intersection entiteit moet je zien als een soort kaartje. Op ieder kaartje staat een combinatie van een evenement en een bedrijf. Soms, zoals hier, kun je ook nog andere attributen aan de intersection entiteit toevoegen.
5.3 Opdrachten#
Opdracht 5.3.1 Maak een matrix bij de volgende entiteiten: garagebedrijf, auto, persoon
Opdracht 5.3.2 Verbeter het volgende ERD:

Opdracht 5.3.3 Verbeter het volgende ERD, die gaat over een busmaatschappij waarbij de passagiers vooraf via internet een bepaalde lange afstands bus moeten boeken:
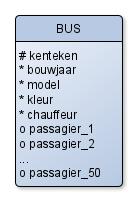
Opdracht 5.3.4 Verbeter het volgende ERD:

Opdracht 5.3.5 Verbeter het volgende ERD:

Opdracht 5.3.6 Los de volgende meer-meer relatie op:
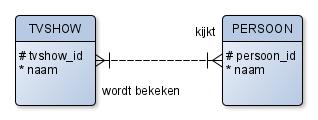
6. Van ERD naar SQL-DDL#
Een genormaliseerde ERD is het resultaat van fase 2 van het ontwerpen van een informatiesysteem. Het is dan tijd om fase 3, het fysieke ontwerp in te gaan. In deze fase ga je de tabellen en de relaties tussen deze tabellen daadwerkelijk in SQL-code omzetten.
Bekijk de onderstaande ERD.
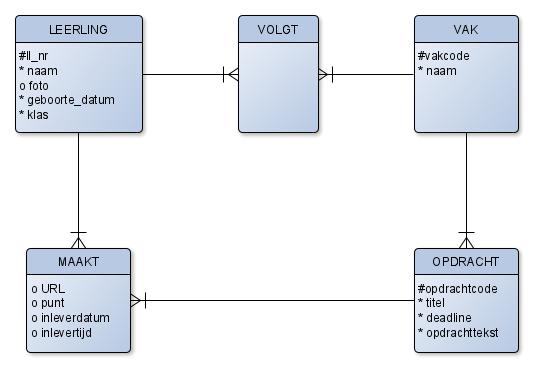
**Is deze ERD daadwerkelijk in 1e, 2e en 3e normaalvorm? **
Zijn alle meer-meer relaties opgelost?
Wanneer je antwoord op beide vragen ja is, dan kun je doorgaan met fase 3.
Om hier SQL-DDL code van te maken, ga je als volgt te werk:
Elke entiteit wordt een tabel
Identificeer de primaire sleutels in een relatie (de UID). Deze geef je dikgedrukt weer.
Identificeer de vreemde sleutels in een relatie (verwijzingen naar andere primaire sleutels). Deze geef je weer tussen
<en>Dit levert je een relationeel model op.
Het relationele model zet je om in SQL-DDL
6.1 Stap 1 t/m 4#
De bovenstaande ERD geeft je het volgende relationele model:
leerling(ll_nr, naam, geboorte_datum, foto, klas)
volgt(<ll_nr>, <vakcode>)
vak(vakcode, naam)
opdracht(opdrachtcode, titel, opdrachttekst, deadline, <vakcode>)
maakt(<opdrachtcode>,<ll_nr>, URL, inleverdatum, inlevertijd, punt)
Merk op dat:
de relatie maakt een primaire sleutel heeft die bestaat uit twee vreemde sleutels.
er nog niet aangegeven staat welke attributen optioneel of verplicht zijn.
6.2 Stap 5#
Een database specificatie in het relationele model kun je eenvoudig omzetten naar een specificatie in SQL. Let op dat je nu dus een keuze maakt in welk DBMS je je database gaat maken. Wij kiezen voor SQL, maar andere opties zijn er ook. Denk aan NoSQL-oplossingen.
Tot nu toe ben je vooral bekend met SQL-DML. Dit staat voor SQL Data Manipulation Language. Met dit deel van SQL kun je gegevens opvragen, veranderen, invoeren of verwijderen uit een database. Je kent dit als de SELECT ... FROM-statements, die je in het eerste deel van deze module hebt leren schrijven.
Het deel van SQL, waar je nu in gaat werken, heet SQL-DDL. Dit staat voor SQL Data Definition Language. Kort gezegd kun je met deze SQL-statements tabelstructuren definiëren en aanpassen. Het relationele model is uitstekend geschikt om naar SQL-DDL te vertalen. De entiteit leerling vertaalt zich naar het volgende SQL-DDL statement:
CREATE TABLE leerling (
ll_nr CHAR(6) NOT NULL,
naam VARCHAR(20) NOT NULL,
geboorte_datum DATE NOT NULL,
foto BLOB,
klas VARCHAR(5) NOT NULL,
PRIMARY KEY(ll_nr)
);
Je vertelt de database letterlijk om een tabel aan te maken met de naam leerling, die bestaat uit de velden ll_nr, naam, geboorte_datum, foto en klas. Het veld ll_nr is bovendien de primaire sleutel. Elke veld geef je ook een passend type. Voor een volledig overzicht van toegestane types in SQL, bekijk dit overzicht. Met NOT NULL geef je aan dat een veld verplicht is en dat NULL niet toegestaan is als waarde. Met andere woorden: het veld mag niet leeg zijn.
Uit je ERD is al duidelijk welke waarden verplicht of optioneel zijn. Deze informatie kun je dus overnemen in je SQL-DDL.
Een relatie met een vreemde sleutel, zoals maakt vertaal je vergelijkbare wijze. Er komen enkel twee vreemde sleutels bij in de specificatie.
CREATE TABLE maakt(
opdrachtcode INTEGER NOT NULL,
ll_nr CHAR(6) NOT NULL,
url VARCHAR(50),
inleverdatum DATE,
inlevertijd TIME,
punt NUMERIC(3,1),
PRIMARY KEY(opdrachtcode,ll_nr),
FOREIGN KEY(opdrachtcode) REFERENCES opdracht,
FOREIGN KEY(ll_nr) REFERENCES leerling
);
Net zoals je aangeeft welke velden de primaire sleutel vormen, zo geef je aan welke velden een vreemde sleutel vormen; hiermee maak je aan de database duidelijk welke relaties er in je tabelstructuur zitten. Bij een FOREIGN KEY moet je niet alleen een veld uit die tabel aangeven, maar ook een verwijzing naar een andere tabel. Dit doe je met het keyword REFERENCES.
Let op dat de vreemde sleutels precies hetzelfde type hebben als de primaire sleutel waarnaar ze verwijzen!
Indien een vreemde sleutel dezelfde naam heeft als een al bestaand veld in de tabel, hernoem dan de vreemde sleutel. Een naam kan in een tabel maar één keer gebruikt worden.
Laatste belangrijke opmerking: elk SQL-statement moet je afsluiten met een ;. Dat geldt eigenlijk ook voor queries in SQL-DML, maar daar wordt meestal niet zo streng op gelet ;-)
6.3 Opdrachten#
Opdracht 6.3.1
Maak de CREATE TABLE definities voor de relaties volgt, vak en opdracht uit het gebruikte voorbeeld hierboven.
Opdracht 6.3.2 Bekijk de volgende ERD.
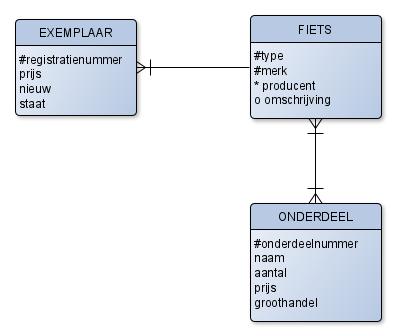
Opmerkingen:
Type, merk, naam en producent zijn korte stukjes tekst als “Gazelle”, “City Explorer”, “Terrain beast”
De staat is: goed, redelijk of slecht
De prijs heeft twee cijfers achter de komma
Het veld
nieuwgeeft aan of een fiets nieuw is of tweedehands.
a) Indien nodig: verwijder meer-meer relaties.
b) Maak een relationeel model van deze ERD
c) Zet dit relationele model om naar een database specificatie in SQL.
7. Eindopdracht#
Bijgewerkt op 2024-10-03:
LET OP: in 2024-2025 is dit aangepast, mocht je de module eerder gedaan hebben en verder willen gaan met iets waar je toen al aan begonnen was, neem even contact op met de docent.
7.1 Beoordelingscriteria#
Je werkt alleen. Samenwerken is niet toegestaan. Ieder levert een unieke uitwerking in.
Je levert al je werk op in een leesbaar en gestructureerd document, zodat het geen zoekplaatje voor je docent wordt.
ERD-diagrammen mag je met potlood tekenen en scannen/fotograferen: zolang het maar leesbaar is.
Je mag de ERD diagrammen ook maken met yEd of https://draw.io/ .
Van je gekozen casus werk je het volgende uit. Er zijn 20 punten te verdienen en twee bonuspunten voor een uitwerking in SQL-DDL voor een model.
De ERD-ish zinnen (7 punten)
Het entiteit-relatie-diagram (ERD) (8 punten)
In het ERD zitten geen “problemen”, dus geen dubbel opgeslagen gegevens en geen meer-meer relaties
Een “fysiek” relationeel model van je casus: (5 punten)
welke tabellen zijn er (elke entiteit heeft een tabel)
welke kolommen heeft elke tabel
wat is het type (tekst, getal, datum, …) van elke kolom
welke keys (primariy keys / foreign keys) heeft de tabel
(Optioneel) Een SQL-DDL van je casus (2 bonuspunten)
Dit zijn CREATE queries in SQL.
Dit mag je doen; je kunt er alleen bonuspunten mee scoren.
De maximale score is een 10, ook met de theoretische 22 punten.
Zet deze onderdelen in een leesbaar en gestructureerd document. Gestructureerd wil zeggen dat je netjes hoofden, inhoudsopgave en paginanummers gebruikt.
Bij het nakijken zal ik letten op:
De vorm van je ERD-ish zinnen (zie voor de vorm van deze zinnen hoofdstuk 4)
ERD: opgeloste meer-meer relaties, primaire sleutels, verplichte/optionele attributen, kraaienpoot-notatie, naamgeving, attribuut-eigenschappen,de lijnen en of het overzichtelijk is weergegeven.
“Fysiek” model: komt elke entiteit uit je ERD voor in je logisch model als tabel, de sleutels, zijn de attributen zinnig.
Als je een SQL script meelevert: is het correcte syntax (ik ga het misschien gewoon wel uitproberen!) Dit levert alleen bonuspunten op.
7.2 Hoe ga je te werk#
Bedenk eerst wat de entiteiten zijn. Bij een spel zijn dat bijvoorbeeld spelers, (npc) karakters, ruimtes of iets op het bord, kaartjes met effecten, …
Bedenk welke relatie de entiteiten tot elkaar hebben en beschrijf de relaties in ERDish-zinnen
Werk de relaties uit in een ERD diagram
Bedenk dan welke eigenschappen elke entiteit heeft
Werk de eigenschappen uit in een tabel van attributen en typen, geef een eventuele waardebeperking aan.
7.3 Voorbeelden van casussen#
Het thema voor dit blok is dieren. Je mag zelf een casus bedenken, je mag ook onderstaand verhaal gebruiken voor je database-ontwerp.
Dierentuin#
In onze dierentuin leven verschillende diersoorten. Ze leven in mooie verblijven, waar bezoekers ze kunnen bekijken. Sommige diersoorten mogen bij elkaar in een verblijf, andere soorten kunnen we beter gescheiden houden (anders houden we minder dieren over, zegmaar). De dieren hebben uiteraard voer nodig, dat per diersoort kan verschillen. En ze worden verzorgd door onze heel aardige verzorgers.
Hiervoor hebben we een informatiesysteem nodig; niet voor de verzorgers / personeel; daar hebben we al een systeem voor. We willen een systeem hebben dat alle dieren in kaart brengt.
Appendix: Versie historie van deze syllabus#
Hoofdstukken 2 t/m 5 zijn afkomstig van de cursus Databasedesign van het SLO, geschreven door Eelco Dijkstra. Hoofdstuk 6 maakt gebruik van het materiaal van Heer deBeer.
In 2023 is deze syllabus verder aangepast door docent Merijn Vogel.